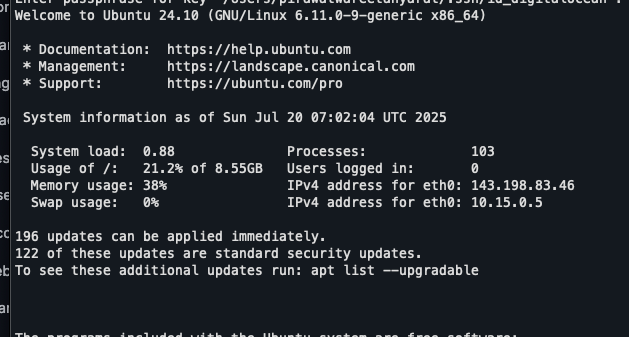
สวัสดีครับวันนี้เห็นผมเห็นไลฟ์ระหว่างนายอาร์มกับคุณเท้ง ซึ่งตัวผมก็ทำงานอยู่ในแวดวงราชการอยู่แล้ว ก็เลยนั่งฟังแล้วก็สรุปโดยให้ AI ช่วยเรียบเรียงภาษาและเป็นหัวข้อครับ
การเขียน TOR ปัจจุบันขาดมาตรฐาน ต่างคนต่างจ้าง ทำให้โครงการบวมและตรวจสอบยาก
นอกจากเรื่อง TOR แล้วราชการก็ขาดคนที่มีความสามารถ ทำให้ต้องจ้างคนนอกมาเขียน TOR ( ที่ปรึกษา ) ซึ่งคนเหล่านี้เก่งจริงแต่ไม่ใช่คนที่คลุกคลีอยู่ในงานทำให้ขาดการกำหนด TOR
ports: ใช้กำหนดการเชื่อมโยง Port ระหว่าง Container ภายใน กับ Port ของเครื่อง VM ภายนอก (เช่น - 80:80 คือ Port 80 ภายนอกเชื่อมไป Port 80 ภายใน Container)
# Replace <directory-path> with the path where you created folders earlier
DATA_FOLDER=/<directory-path>/n8n-docker-caddy
# The top level domain to serve from, this should be the same as the subdomain you created above
DOMAIN_NAME=example.com
# The subdomain to serve from
SUBDOMAIN=n8n
# DOMAIN_NAME and SUBDOMAIN combined decide where n8n will be reachable from
# above example would result in: https://n8n.example.com
# Optional timezone to set which gets used by Cron-Node by default
# If not set New York time will be used
GENERIC_TIMEZONE=Europe/Berlin
# The email address to use for the SSL certificate creation
SSL_EMAIL=example@example.com
# Replace <directory-path> with the path where you created folders earlier
DATA_FOLDER=/demo/n8n-docker-caddy # ผมแนะนำว่าให้สร้างที่อื่นนะครับของจริง ผมสร้างใน /etc
# The top level domain to serve from, this should be the same as the subdomain you created above
DOMAIN_NAME=patrawi.com
# The subdomain to serve from
SUBDOMAIN=n8n
# DOMAIN_NAME and SUBDOMAIN combined decide where n8n will be reachable from
# above example would result in: https://n8n.example.com
# Optional timezone to set which gets used by Cron-Node by default
# If not set New York time will be used
GENERIC_TIMEZONE=Asia/Bangkok
# The email address to use for the SSL certificate creation
# SSL_EMAIL=example@example.com
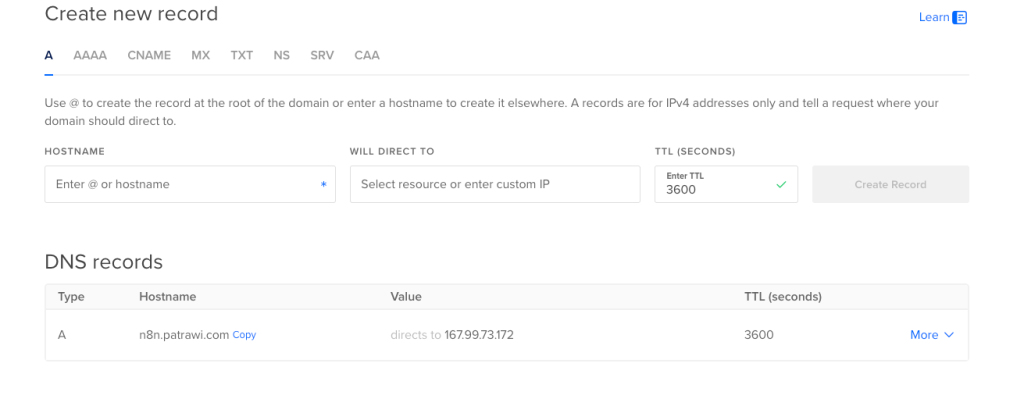
สำหรับตรงนี้ผมก็จะแก้เป็น n8n.patrawi.com ที่เป็น domain ที่ผมซื้อไว้นั้นเอง อย่างไรก็ตาม หากเป็นการใช้งานในหน่วยงานของท่าน คุณจะต้องแจ้งทีม Network ให้เขากำหนด subdomain และ DNS recordให้เราอีกทีนะครับ เพื่อที่ DNS มองเห็น IP Address ของ VM ของคุณครับ
เริ่มต้นและตั้งค่า DNS
เมื่อแก้ Config ทั้งหมดเสร็จแล้ว ได้เวลา Spin up Container ของเราแล้วเย้
sudo docker compose up -d
แต่ว่าพอคุณ เปิดไปที่ dns ที่คุณกำหนดแล้ว คุณก็จะพบว่าข้อความ Can’t Reach This Server สาเหตุก็เป็นเพราะว่า DNS ของเรานั้นยังไม่ได้นำไปผูกกับ IP Address ที่ DigitalOcean นั้นเองเราก็จะต้องไปทำตรงนั้นกันก่อน
*หมายเหตุ ถ้าเราให้ทีม network ของหน่วยงานเราเป็นคนสร้าง vm ขึ้นมาให้ตรงจุดนี้จะไม่มีปัญหานะครับ แต่จะไปมีปัญหาเรื่อง SSL/TLS แทนเดี๋ยวผมจะวนมาอธิบายให้ฟังอีกทีครับ
ขั้นตอนการตั้งค่า DNS บน DigitalOcean (หรือผู้ให้บริการ DNS ของคุณ):
ตลอดระยะเวลา 6 สัปดาห์ (ที่เหลือขอไม่นับละกันครับ เพราะเป็นของฝึกงานที่คณะที่ผมเรียนแล้ว) ด้วยความว่าเป็นงานด้าน IT งานส่วนใหญ่ที่ผมเข้าไปเรียนรู้เนื้องานก็จะเป็นพวก Database & Web development, Network & Security, IT Support
ตอนนั้นด้วยความว่า ไอ้เรามันก็คนร้อนวิชาอยู่พอตัว ก็เลยขอเขาลอง POC (Proof Of Concept) เกี่ยวกับการทำ Line Chatbot ด้วย Line Messaging API เพื่อใช้แจ้งรายการอาหารในแต่ละสัปดาห์ก่อนที่จะหมด 5 สัปดาห์พอดี
เป็นเวลาหลายเดือนที่ผมเรียนจบจาก Data Science Bootcamp กับ Ad’ Toy และได้เริ่มเขียน Posts หลายๆอัน หลังจากมัวไต่แรงก์ TFT Set 14 ผมว่ามันถึงเวลาอันสมควรแล้วที่จะเขียน Post เพื่อทบทวนและแชร์ไอเดียเกี่ยวกับ Classical Machine Learning ที่ผมได้เรียนในคอร์สกับ Ad’ Toy
แต่ครั่นจะให้ผมแค่อธิบายสิ่งที่ได้เรียนมาในคอร์สก็ดูจะเบสิคเกินไป ผมจะพาทุกท่านไปดูการทำและวิเคราะห์ไอเดียผ่าน data ใน kaggle แทนเพื่อให้ทุกท่านได้เห็นภาพมากขึ้น
โดยในส่วนของ Main Series นั้นเราจะโฟกัสไปที่การแตะๆ Walkthrough เนื้อหาภาพรวมกันเสียก่อน แล้วเดี๋ยวเราค่อยมาเจาะลึกกันสำหรับแต่ละ Algorithms ใน Series ถัด
# Mean Absolute Error Trained 61.831639475521364
# Mean Absolute Error Test 60.9002976731785
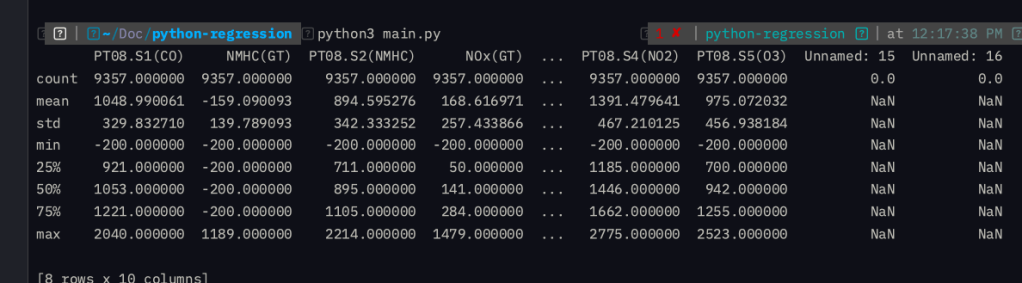
หน่วยที่ใช้วัดจะเป็นหน่วย µg/m³ ไมโครกรัม ต่อ ลูกบาศก์เมตร หากดูจากค่า trained MAE และ test MAE นั้นถือว่ามีค่าใกล้กันแต่แปลว่า model เราค่อนข้าง generalised
อย่างไรก็ตาม MAE เป็นค่าที่ยิ่งใกล้ 0 จะยิ่งให้ผลลัพธ์ที่ดีเพราะแปลว่าเราอ่านค่าคลาดเคลื่อนน้อย แต่นี้ MAE ตั้ง 60 แปลว่า simple linear regression model ไม่ตอบโจทย์กับ dataset นี้
เพราะฉะนั้นเรามาลองหาค่าใหม่แต่ใช้เป็น multi-varaible linear regression กันอีกรอบ
จากตัวอย่างข้างต้นทำให้เราได้ข้อสรุปว่าการที่เราจะ train model อะไรซักอย่างนั้นจะต้องลองหลายๆ model เพื่อหา model ที่ดีที่สุดทั้งในเรื่องของเวลาและค่าใช้จ่าย
ซึ่งนี้เป็นไปตามหลักการที่ว่า ไม่มีโมเดลไหนเก่งที่สุด และสามารถตอบโจทย์ได้ทุกปัญหา หรือ No Free Lunch บางทีอาจจะมีโมเดลอื่นอย่าง Decision Tree, Random Forest และ อื่นๆ ที่จะสามารถนำ data นี้ไปทำนายได้อย่างมีประสิทธิภาพมากขึ้นไปอีกได้เช่นกัน
Conclusion & Evaluation
สรุป dataset นี้ไม่เหมาะที่จะใช้ Linear Regression model ในการทำนายค่าเนื่องจากว่ามีผลลัพธ์ที่ไม่น่าพึ่งพอใจและเสี่ยงตอนความคลาดเคลื่อนสูง
จากที่ ผมลองดูมา dataset ใน kaggle ที่ดูแล้วน่าจะใช้ Linear Regression ได้ก็น่าจะเป็น California Housing Price ครับเพื่อนๆก็สามารถลอง ขั้นตอน cleansing data (preprocessing) บวกกับ การสร้าง Linear Regression Model ที่ผมเขียนไปลองดูกันได้ ลองแล้วได้อย่างไรก็อย่าลืมมาแชร์กันนะครับ
Scatter Plot ของ y_pred, X_test
แล้วเพื่อนๆ เคยเจอโปรจคไหนที่มีปัญหา No Free Lunch อย่างนี้ไหมครับ
แล้วถ้าเกิดว่าวันนึง มันดันมีเทคโนโลยีที่สามารถแก้ปัญหาตรงนี้ได้ละ เทคโนโลยีที่จะช่วยให้เราสแกนเอกสารและทำออกมาเป็นไฟล์พร้อมนำเข้าข้อมูล บนโปรแกรต่างๆไม่ว่าจะเป็น Spreadsheet, Excel หรือ โปรแกรมจากการเขียนโค้ดอย่าง python หรือ R คุณลองคิดดูสิว่าขยะเหล่านี้จะมีค่าแค่ไหน ? เพราะฉะนั้น วันนี้ผมจะพาทุกท่านมารู้จักกับ AI จากทาง Google อย่าง Gemini Flash 2.5 ที่เราสามารถทดสอบ บนGoogle AI Studio ซึ่งจะเข้ามาช่วยแก้ปัญหาและอุด Pain Point นี้กันครับ
เสาะหาซึ่งหนทาง: การมาถึงของ Google AI Studio
ในช่วงแรกที่เหล่า Data Scientists ต้องแก้ปัญหานี้ พวกเขาก็พยายามค้นหาวิธีการต่างๆ อาทิเช่น การ Scan ข้อมูลเหล่านั้นเป็น PDF Copy/Paste บ้างละ ใช้โปรแกรม online สำหรับแปลง PDF ไปเป็น CSV บ้างละ ไปจนถึงขั้นยอมเสียเงินจำนวนมากเพื่อซื้อโปรแกรมมาปิดจุดอ่อนนี้
ด้วยการมาถึงของยุคที่ Generative AI เป็นที่รู้จักแพร่หลาย บริษัท Google ก็ไม่น้อยหน้าปล่อย แพลทฟอร์ม ออกมาให้ผู้ใช้งานอย่างเราๆได้ทดลองใช้ฟรี โดยเราสามารถเข้าไปลองเล่น Model ต่างๆของทาง Google ผ่านทาง Google AI Studio
ทำไมต้อง Google AI Studio ทั้งๆ ที่เจ้าอื่นก็มีแพลตฟอร์มทดลองให้ใช้เหมือนกัน? คำตอบง่ายๆ คือ ‘เพราะมันฟรี’ ผู้ใช้งาน Gemini เวอร์ชั่นปกติอาจเข้าถึงได้แค่ Gemini Flash แต่ใน Google AI Studio คุณสามารถใช้งาน Gemini Pro ได้ฟรีไม่จำกัด นี่คือข้อได้เปรียบสำคัญที่ไม่อาจมองข้าม
แถมเรายังสามารถปรับแต่งค่าต่างๆเพื่อให้ AI ตอบคำถามตามความต้องการของเราได้ เช่น ตั้งค่า Temperature ต่ำ หรือ สูง เพื่อกำหนดความสร้างสรรค์ของ AI กำหนด output length ว่าจะให้ตอบได้ไม่เกินครั้งละเท่าไหร่ ไปจนถึงการกำหนด Top P เพื่อควบคุมความหลากหลายของคำตอบ โดยให้ AI เลือกจากกลุ่มคำที่มีความน่าจะเป็นสูงสุด
อีกหนึ่งสิ่งที่ น่าประทับใจมากๆของ Google AI Studio ก็คือจำนวน Context window ที่ให้มาอย่างจุใจถึง 1 ล้าน ส่งผลให้การคุยของผู้ใช้งานนั้นราบรื่นอย่างไร้ปัญหา และด้วยเหตุนี้ Google AI Studio จึงเหมาะมากที่เราจะใช้เพื่อ POC concept ของเราสำหรับประยุกต์ใช้ในอนาคตนั้นเอง
ช่วงของการลองผิดลองถูกการประยุกต์ใช้ Google AI Studio เพื่อการอ่าน PDF
สำหรับจุดประสงค์ในการทำครั้งนี้ก็คือการที่เราสามารถอ่านไฟล์สแกน PDF ได้เป็นจำนวนมากเพื่อที่จะดึงข้อมูลจากกระดาษออกมาและ insert เข้าฐานข้อมูล
ด้วยเหตุนี้ เพื่อให้ได้มาซึ่ง tools ที่ตอบโจทย์เรามากที่สุด จึงมีความจำเป็นว่าเราต้องทดลองใช้ Model ที่กูเกิ้ลมีนั้นมาทดสอบเสียก่อน โดยในเคสนี้เราจะทดสอบด้วยโมเดล 2.5 Flash และ 2.5 Pro
ความแตกต่างระหว่าง Pro Model & Flash Model
Pro Model – เป็น โมเดลที่ถูกสร้างมาสำหรับการคิดอย่างเป็นตรรกะ (reasoning), การโค้ดดิ้ง (Coding) และความเข้าใจในหลากหลายมิติ ( Multimodal understanding ) เพื่อใช้ในการคิดวิเคราะห์ปัญหาที่ซับซ้อน ส่งผลให้มีค่า Latency ที่สูงเพราะ Model จำเป็นต้องคิดไปทีละ Step ก่อนที่จะได้รับคำตอบ
Flash Model – สำหรับ Flash Model นั้นถูกออกแบบมาให้ใช้กับงานประมวลผลเป็นจำนวนมากเช่น ไฟล์ PDF หลายๆไฟล์ งานที่ต้องการ latency ตำ่และรับ input ได้เยอะ, หรือ agentic use cases
จากข้อมูลข้างต้นเราจึงควรเลือกใช้ Flash Model เพราะด้วยความที่ Latency ต่ำ + กับเหมาะทำงานซ้ำๆ ถือว่าตอบโจทย์ของเราเป็นอย่างมาก
หลังจากที่เลือก Model เรียบร้อยแล้วเรามาดูขั้นตอนในการทำงานก่อนดีกว่า
ใน ช่วง Proof cf Concept นั้น เราไม่จำเป็นที่จะต้องใช้ API_KEY โดยเราสามารถ Log in Gmail และใช้งานบน แพลทฟอร์ม Google AI Studio ได้เลย
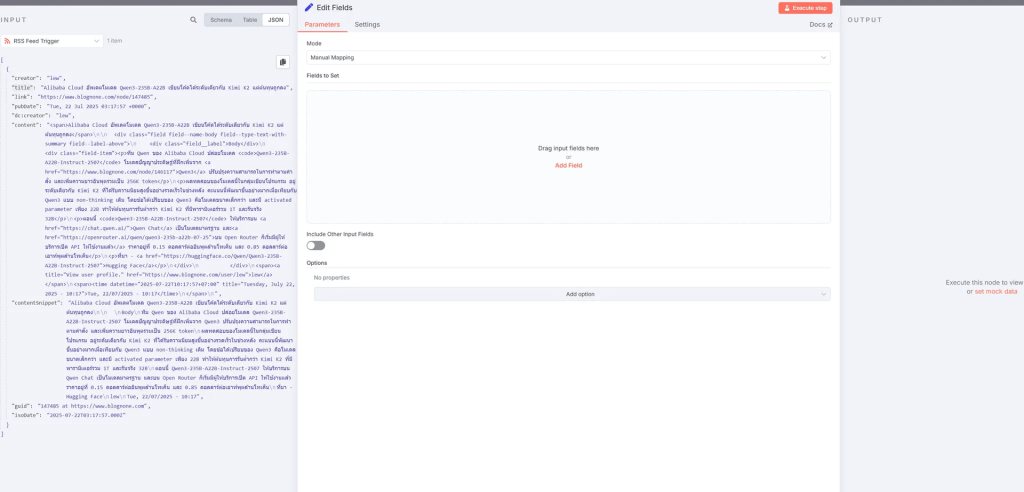
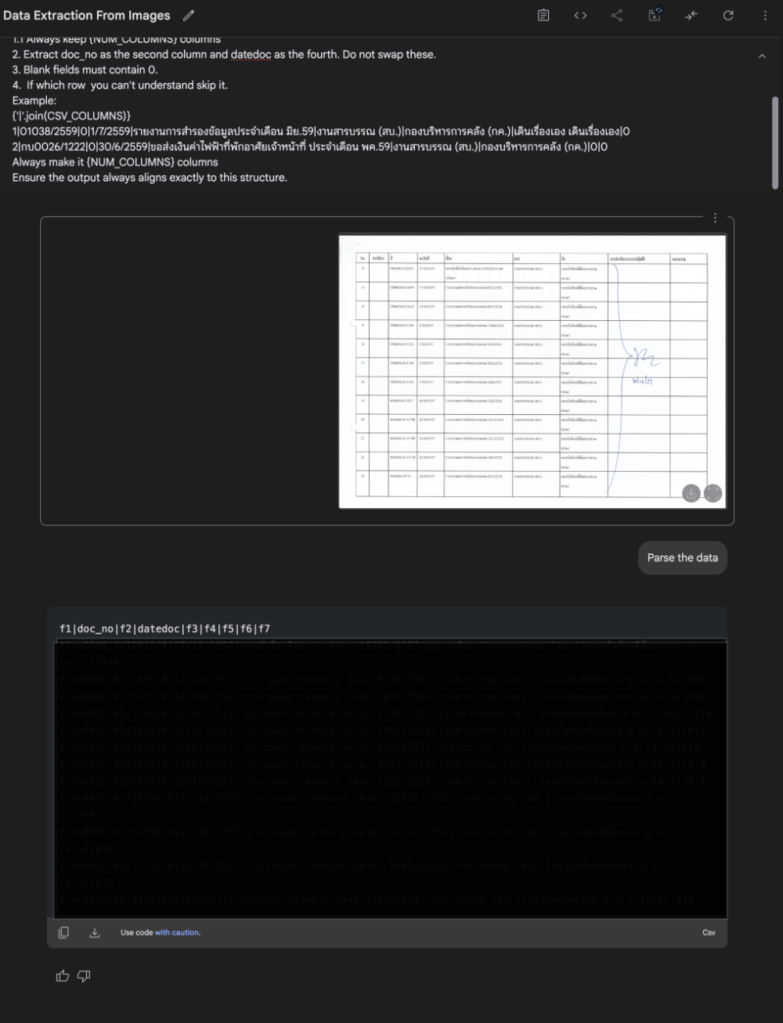
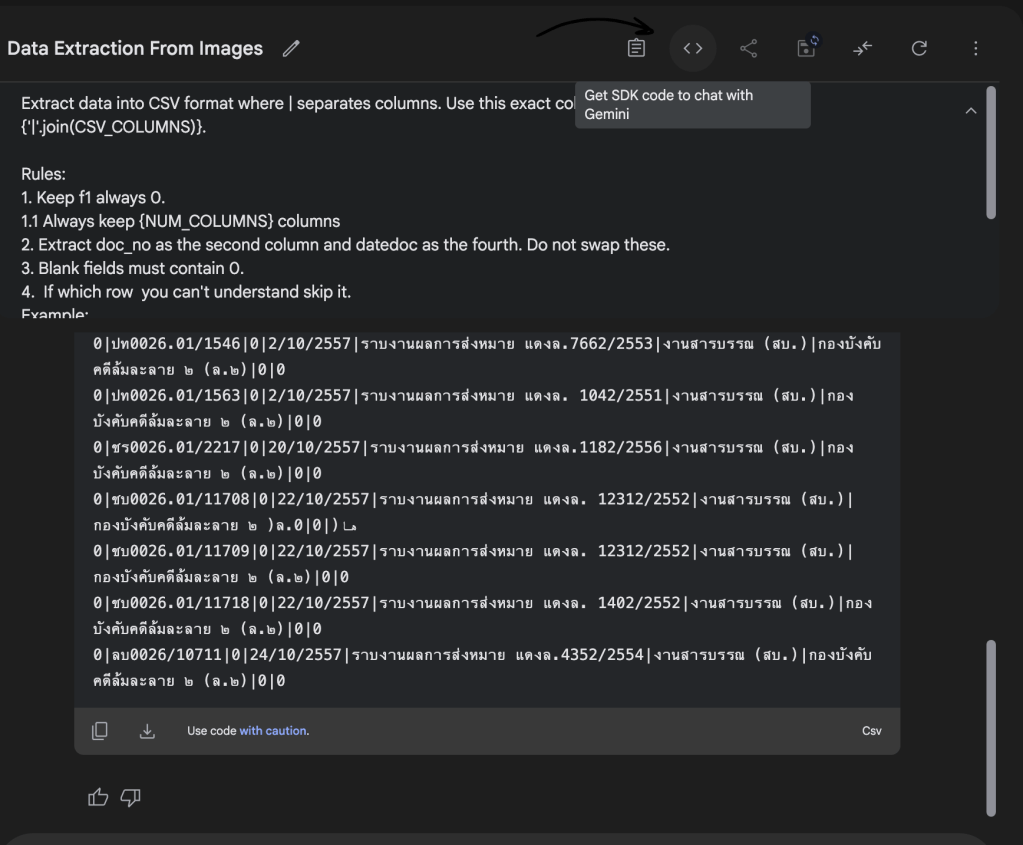
จากนั้นทำการอัพโหลดรูปภาพเข้าไป และพิมพ์ System Instruction ดังนี้
Extract data into CSV format where | separates columns. Use this exact column order:
{'|'.join(CSV_COLUMNS)}.
Rules:
1. Keep f1 always 0.
1.1 Always keep {NUM_COLUMNS} columns
2. Extract doc_no as the second column and F as the fourth. Do not swap these.
3. Blank fields must contain 0.
4. If which row you can't understand skip it.
Example:
{'|'.join(CSV_COLUMNS)}
1|0000/2559|0|1/7/2559|รายงานการสำรองข้อมูลประจำเดือน มิย.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|เดินเรื่องเอง เดินเรื่องเอง|0
2|กบ0000/1222|0|30/6/2559|ขอส่งเงินค่าไฟฟ้าที่พักอาศัยเจ้าหน้าที่ ประจำเดือน พค.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|0|0
Always make it {NUM_COLUMNS} columns
Ensure the output always aligns exactly to this structure.
จากนั้นทำการกด Run และรอผลัพธ์
จะเห็นได้ว่าเราได้ข้อมูลในรูปแบบ CSV พร้อมนำไปใช้ในขั้นตอนต่อไปได้ทันที! แต่หากเราไม่ได้กำหนด System Instruction หรือ Prompt ที่ชัดเจนและรัดกุมแล้วละก็ เราอาจได้ข้อมูลในรูปแบบที่ไม่ใช่ CSV หรือได้ Format ที่ไม่น่าพึงพอใจ เพราะฉะนั้น ‘หลักการ Prompt Engineering’ จึงสำคัญอย่างยิ่งมากในการดึงศักยภาพของ AI ออกมาใช้ได้อย่างเต็มที่.
ผู้อยู่เบื้องหลังทุกสิ่ง อธิบายเกี่ยวกับ Gemini 2.5 Flash Model
ทุกสิ่งทุกอย่างข้างต้นนั้นล้วนเกิดจากข้อมูลมหาศาลที่โมเดลได้รับการเรียนรู้มาแล้วล่วงหน้า ผสมผสานกับวิธีทางคณิตศาสตร์ที่ซับซ้อน ส่งผลให้ AI สามารถวิเคราะห์และคาดเดาได้อย่างแม่นยำว่าข้อมูลที่อยู่บน PDF เหล่านั้นคืออะไร และควรจะจัดเรียงออกมาในรูปแบบใด
หลักจากที่ได้อธิบายว่า AI นั้นมันน่าอัศจรรย์มากขนาดไหน เพราะหลังจากนี้เราไม่จำเป็นต้องหามรุ่งหามค่ำนั่งกรอกข้อมูลกันเป็นพันลวันแล้ว เรายังสามารถต่อยอดทำให้มัันอัตโนมัติได้ยิ่งขึ้นไปอีกด้วยนะAIM
หากเราเข้าไปที่ตรงหน้า chat ที่เราคุยกับ gemini ใน google ai studio
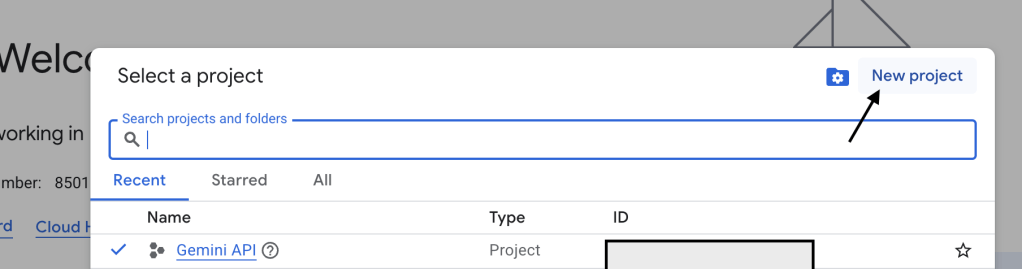
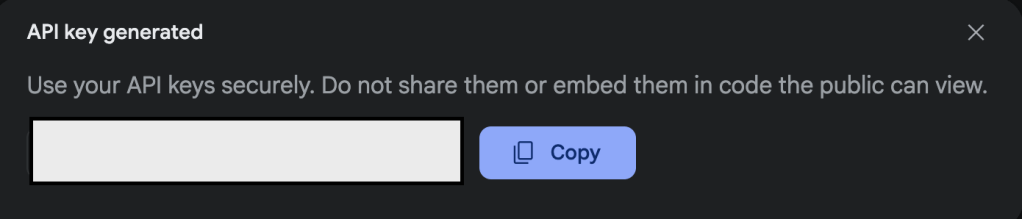
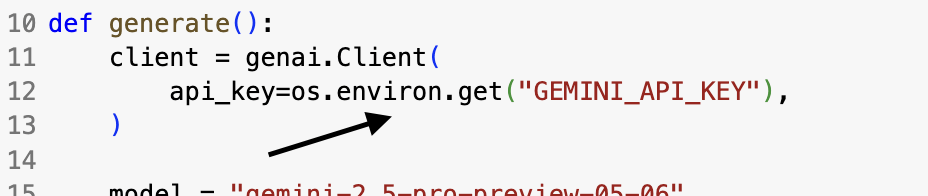
แต่ว่าการที่จะทำให้โค้ดนี้สมบูรณ์ได้นั้นเราต้องใช้ GEMINI_API_KEY ซึ่งถือเป็นอีกหนึ่งปัจจัยสำคัญเลย โดยการที่จะหามาได้นั้นเราก็แค่กดปุ่มด้านบนที่เขียนว่า Get API Key
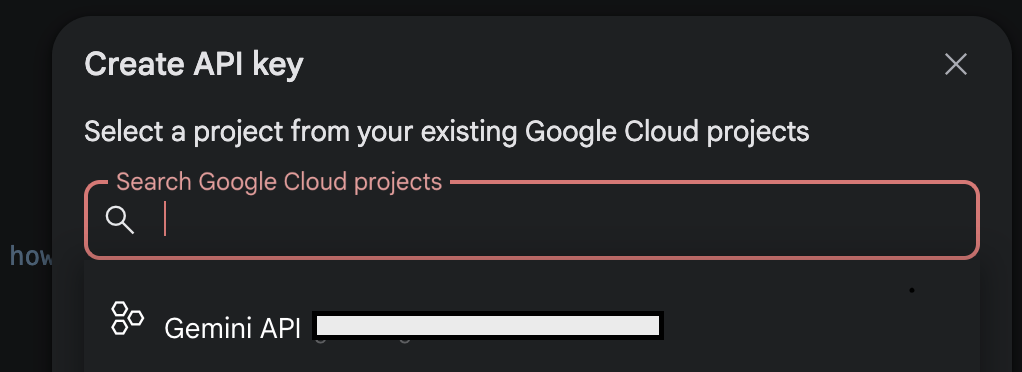
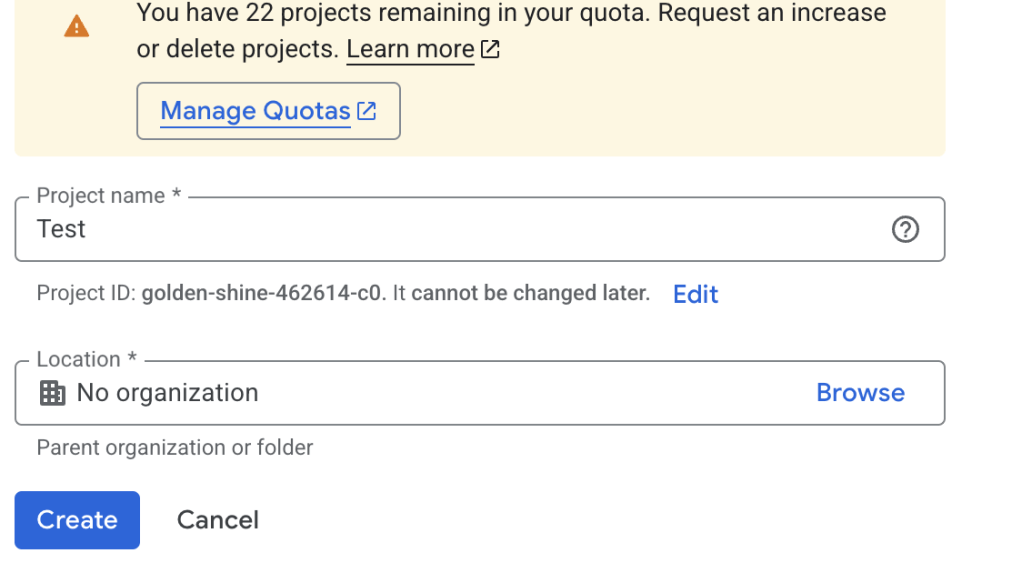
หลังจากนั้นให้ทำการกด + Create API Key google ai studio จะทำการค้นหา Google Cloud Project
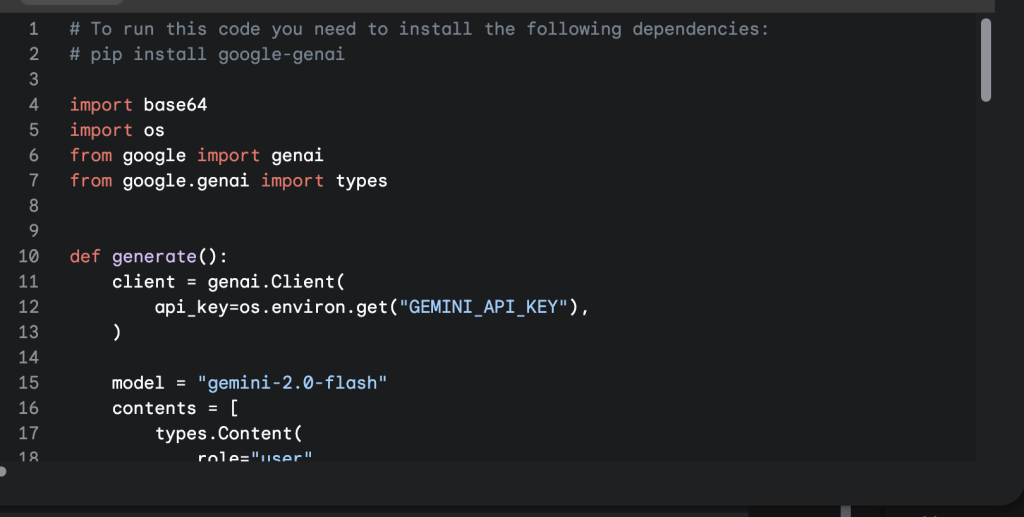
ทีนี้เราก็สามารถทดสอบโค้ดที่ google ai studio ให้มาได้แล้ว เย้
# To run this code you need to install the following dependencies:
# pip install google-genai
import base64
import os
from google import genai
from google.genai import types
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemini-2.5-pro-preview-05-06"
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""INSERT_INPUT_HERE"""),
],
),
]
generate_content_config = types.GenerateContentConfig(
response_mime_type="text/plain",
system_instruction=[
types.Part.from_text(text="""Extract data into CSV format where | separates columns. Use this exact column order:
{'|'.join(CSV_COLUMNS)}.
Rules:
1. Keep f1 always 0.
1.1 Always keep {NUM_COLUMNS} columns
2. Extract doc_no as the second column and datedoc as the fourth. Do not swap these.
3. Blank fields must contain 0.
4. If which row you can't understand skip it.
Example:
{'|'.join(CSV_COLUMNS)}
1|01038/2559|0|1/7/2559|รายงานการสำรองข้อมูลประจำเดือน มิย.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|เดินเรื่องเอง เดินเรื่องเอง|0
2|กบ0026/1222|0|30/6/2559|ขอส่งเงินค่าไฟฟ้าที่พักอาศัยเจ้าหน้าที่ ประจำเดือน พค.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|0|0
Always make it {NUM_COLUMNS} columns
Ensure the output always aligns exactly to this structure."""),
],
)
for chunk in client.models.generate_content_stream(
model=model,
contents=contents,
config=generate_content_config,
):
print(chunk.text, end="")
if __name__ == "__main__":
generate()
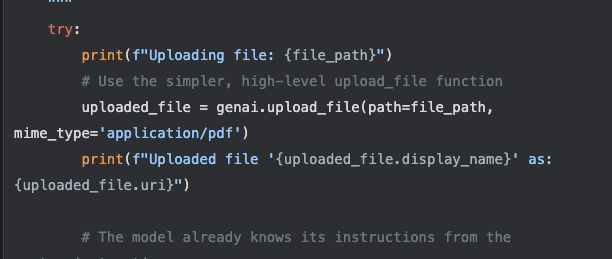
อย่างไรก็ดีโค้ดที่ gemini ให้มานั้นยังทำงานได้แค่กับการ pass ค่า text เข้าไปได้เท่านั้นแถมยังเป็นการรันแบบ ถามตอบแค่ครั้งเดียว ซึ่ง โค้ดดังกล่าวนั้นยังไม่ตอบโจทย์ที่เราต้องนำมาแก้ไขเลย ผมก็เลยมีการแก้โค้ด โดยทำการเพิ่ม method ที่สามารถรับไฟล์เข้าไปเพื่อให้ Gemini Flash Model อ่านผ่าน OCR ได้นั้นเอง
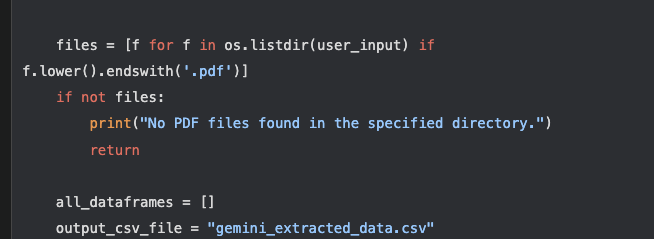
และเมื่อทำการอ่านค่าได้แล้วเราก็ต้องเพิ่มโค้ดอีกนิดนึงว่าแทนที่จะอ่านทีละไฟล์เราก็สร้าง loop ให้โค้ดของเราอ่านผ่านโฟลเดอร์ที่เก็บไฟล์เอาไว้จนกว่าจะหมดแปลงค่าออกมาเป็น csv format ให้เรานั้นเอง
จากการที่เรานำ AI มาประยุกต์ใช้ทำให้ผมไม่ต้องมานั่งกรอกข้อมูลทีละบรรทัดและสามารถอัพข้อมูลเสร็จได้ทั้งสิ้น 265062 ไฟล์ โดยใช้เวลาเพียงแค่ 5 วัน ในการรันโค้ดทั้งหมด แทนที่จะใช้เวลาหลายเดือนนั้นเอง
ผมได้ทดลองให้คุณดูแล้วว่า AI นั้นมีประโยชน์มากแค่ไหนหากเราเข้าใจและใช้มันได้อย่างมีประสิทธิภาพ ผมว่ามันถึงตาคุณแล้วละที่จะต้องลองนำไปประยุกต์ใช้ เพื่อให้งานราชการของเรามีประสิทธิภาพมากขึ้นครับ คุณอาจจะลองเริ่มจากลองใช้ Google AI Studio ก่อนก็ได้ครับมันฟรี ลดกำแพงการศึกษาไปอี๊ก อยากให้คุณได้ลองสัมผัสนะครับ ละจะติดใจแน่นอน
คู่มือย้ายไฟล์: จาก Web Server (Local) สู่ File Server (Remote) ด้วย FileZilla
ในสถานการณ์นี้ เราจะจำลองว่า FileZilla Client ของเรากำลังทำงานอยู่บน Web Server (หรือเครื่องที่เราเข้าถึงไฟล์ของ Web Server ได้โดยตรง) ซึ่งจะแสดงผลเป็น “Local Site” (ฝั่งซ้าย) ใน FileZilla และเราต้องการย้ายไฟล์จาก Web Server นี้ไปยัง File Server ปลายทาง ซึ่งเราจะเชื่อมต่อและให้แสดงผลเป็น “Remote Site” (ฝั่งขวา) ครับ
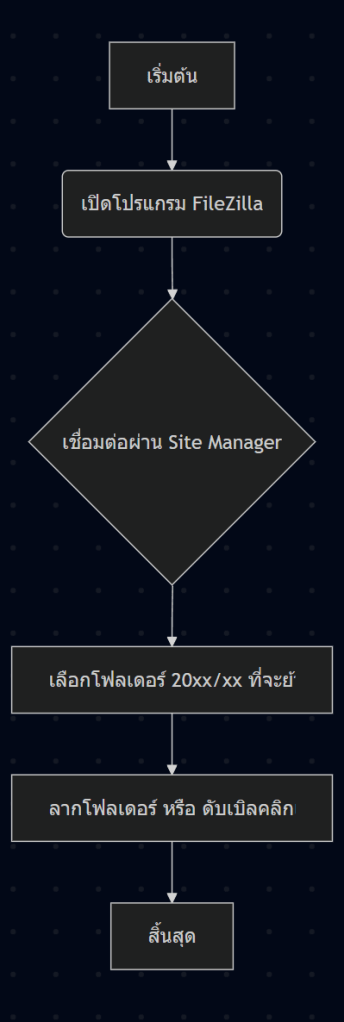
graph TD
A[เริ่มต้น] --> B(เปิดโปรแกรม FileZilla บน Web Server)
B --> C{เชื่อมต่อ File Server ปลายทางผ่าน Site Manager}
C --> D[เลือกไฟล์/โฟลเดอร์บน Web Server (Local Site) ที่ต้องการย้าย]
D --> E[ลากไฟล์/โฟลเดอร์จาก Web Server (Local Site) ไปยัง File Server (Remote Site)]
E --> F[ตรวจสอบความเรียบร้อยและสิ้นสุด]
เอาล่ะครับ มาดูขั้นตอนแบบละเอียดกันเลย:
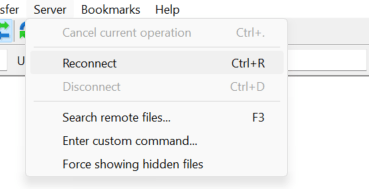
1. เชื่อมต่อ File Server ปลายทาง (Remote Site):
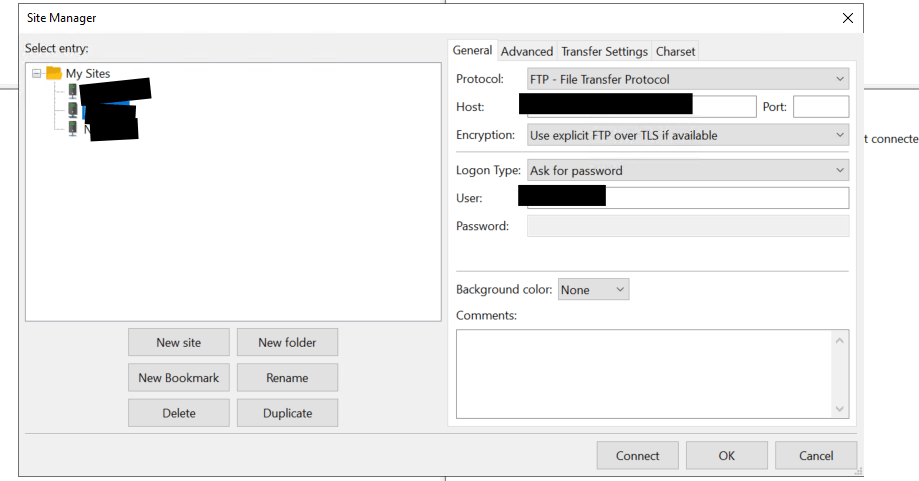
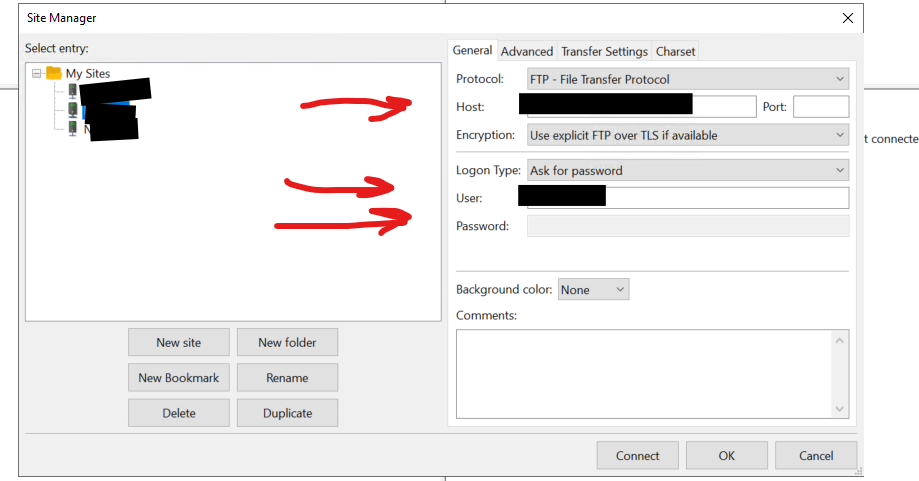
2. หากยังไม่เคยสร้าง Site มาก่อน หรือต้องการเพิ่มการเชื่อมต่อใหม่ ให้คลิกที่ปุ่ม New Site ครับ (ภาพปุ่ม New Site)จากนั้น ตั้งชื่อ Site ของคุณ (เช่น “My File Server”) แล้วกรอกรายละเอียดการเชื่อมต่อที่สำคัญในแท็บ “General” ครับ:
Host: ป้อน IP Address หรือชื่อ Hostname ของ File Server ปลายทาง
Storj (Decentralized Cloud Storage): ตัวเลือกนี้เป็นโปรโตคอลสำหรับการเชื่อมต่อกับบริการ Cloud Storage แบบกระจายศูนย์ที่ชื่อว่า Storj ครับ ซึ่งมักจะเป็นฟีเจอร์ใน FileZilla Pro (เวอร์ชันเสียเงิน) แทนที่จะเป็นการโอนไฟล์ไปยัง Remote Server แบบเดิมๆ ก็จะเป็นการโอนไฟล์ไปยัง Cloud Storage ตาม Region ต่างๆ แทนครับให้เพื่อนๆ เลือก Protocol ที่เหมาะสม (แนะนำ SFTP) จากนั้นตรวจสอบ Port ให้ถูกต้อง (SFTP มักจะเป็น Port 22)
Logon Type (ประเภทการเข้าสู่ระบบ): ผมแนะนำให้เลือกเป็น Ask for password (ถามรหัสผ่านทุกครั้ง) เพื่อความปลอดภัยสูงสุดครับ เพราะถ้าเลือกเป็น Normal โปรแกรมจะบันทึกรหัสผ่านไว้ ซึ่งหากใครเข้าใช้คอมพิวเตอร์หรือ FileZilla ของเราได้ ก็จะสามารถเชื่อมต่อเซิร์ฟเวอร์ได้ทันที เสี่ยงต่อการถูกแฮกได้ครับ (ภาพตัวเลือก Protocol และ Logon Type ใน Site Manager)
4. เริ่มการเชื่อมต่อ:
เมื่อกรอกข้อมูลครบถ้วนและถูกต้องแล้ว กดปุ่ม Connect ได้เลยครับ FileZilla จะพยายามเชื่อมต่อไปยัง File Server ปลายทาง
หากเชื่อมต่อสำเร็จ คุณจะเห็นข้อความสถานะการเชื่อมต่อที่ดี และในหน้าต่างด้านขวา (Remote Site) จะแสดงไฟล์และโฟลเดอร์บน File Server ครับ (ภาพแสดงการเชื่อมต่อสำเร็จ และหน้าต่าง Remote Site ที่มีไฟล์)
5. เตรียมไฟล์และเริ่มโอนย้าย:
ตอนนี้ มาดูหน้าต่างโปรแกรม FileZilla กันครับ:
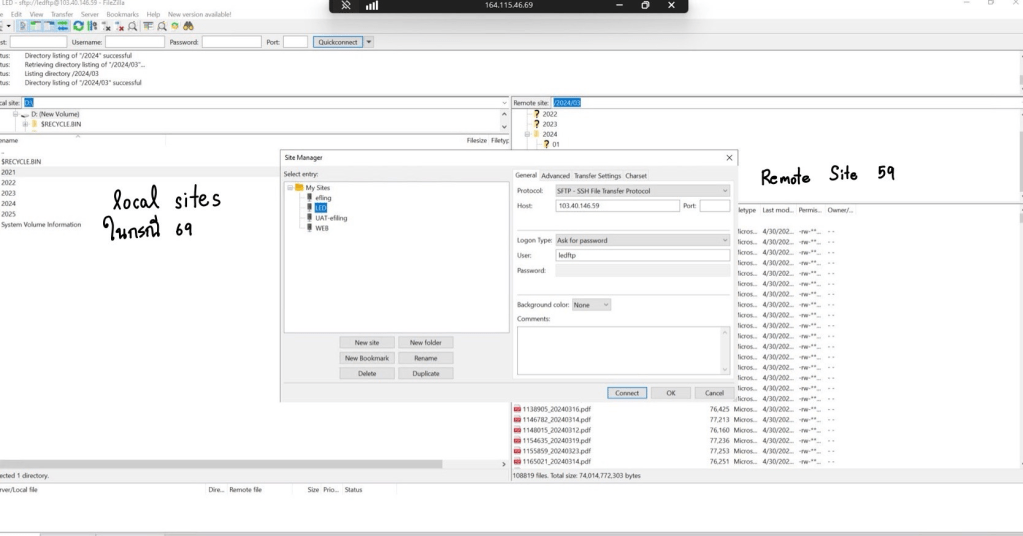
ฝั่งซ้าย (Local Site): นี่คือไฟล์และโฟลเดอร์บน Web Server ของคุณ (เครื่องที่คุณกำลังเปิด FileZilla อยู่ หรือเครื่องที่ FileZilla มองเห็นไฟล์เป็น Local)
ในหน้าต่าง Local Site (ด้านซ้าย – Web Server ของคุณ) ให้ไปยังโฟลเดอร์ที่มีไฟล์ที่คุณต้องการจะย้ายไปยัง File Server ครับ (ภาพแสดงการเลือกไฟล์ใน Local Site)
เลือกไฟล์หรือโฟลเดอร์ที่ต้องการจากฝั่ง Local Site (Web Server) จากนั้น ลาก (drag and drop) ไฟล์หรือโฟลเดอร์เหล่านั้นข้ามไปวางยังตำแหน่งที่ต้องการในฝั่ง Remote Site (File Server) ครับ หรือจะคลิกขวาที่ไฟล์/โฟลเดอร์ต้นทางแล้วเลือก “Upload” ก็ได้เช่นกัน
นอกจาก FileZilla Client ที่เราเน้นใช้งานกันแล้ว ยังมี FileZilla Server ด้วยนะครับ ซึ่งตามชื่อเลยครับ ตัวนี้จะทำหน้าที่เป็น “เซิร์ฟเวอร์” ให้ผู้อื่นเชื่อมต่อเข้ามาเพื่อรับส่งไฟล์ FileZilla Server รองรับโปรโตคอล FTP, FTPS (FTP over SSL/TLS), และ SFTP (สำหรับเวอร์ชัน Pro หรือเมื่อคอมไพล์เองกับไลบรารีที่รองรับ) เพื่อให้มั่นใจว่าไฟล์ที่ส่งผ่านนั้นถูกเข้ารหัสและปลอดภัย
โดยในหน้าจอการตั้งค่า (GUI – Graphical User Interface) ของ FileZilla Server นั้นก็จะมีฟีเจอร์ให้ปรับแต่งได้มากมาย เช่น การสร้าง User และ Group, การกำหนดสิทธิ์การเข้าถึงโฟลเดอร์, การจำกัดความเร็ว, การกรอง IP Address และอื่นๆ อีกมากมายครับ เหมาะสำหรับคนที่ต้องการตั้ง FTP Server ส่วนตัว หรือใช้ภายในองค์กรครับ
จริงๆ แล้วยังมี FileZilla Pro ที่รวมความสามารถทั้ง Client และ Server พร้อมฟีเจอร์ขั้นสูงอีกมากมาย แต่เนื่องจากผมเองยังไม่เคยได้ใช้งานเวอร์ชัน Pro อย่างเต็มรูปแบบ จึงขอละรายละเอียดในส่วนนี้ไว้ก่อนนะครับ
Active Mode (แอคทีฟโหมด): ในโหมดนี้ Client จะเป็นคนเริ่มต้นการเชื่อมต่อ Command Channel (ช่องทางส่งคำสั่ง) ไปยัง Server จากนั้น Client จะ “บอก” Server ว่าจะให้ Server เชื่อมต่อ Data Channel กลับมาหา Client ที่ IP Address และ Port ไหน เมื่อ Server ได้รับข้อมูลแล้ว Server ก็จะเป็นฝ่าย “เริ่มต้น” การเชื่อมต่อ Data Channel กลับมายัง Client ครับ ปัญหามักจะเกิดถ้า Client อยู่หลัง Firewall หรือ NAT Router ซึ่งอาจจะบล็อกการเชื่อมต่อที่เข้ามาจาก Server ครับ
Passive Mode (พาสซีฟโหมด) (เป็นค่าเริ่มต้นใน FileZilla): เพื่อแก้ไขปัญหาของ Active Mode จึงเกิด Passive Mode ขึ้นมาครับ ในโหมดนี้ Client จะเป็นคนเริ่มต้นทั้ง Command Channel และ Data Channel ครับ โดย Client จะส่งคำสั่ง PASV ไปยัง Server จากนั้น Server จะตอบกลับมาพร้อมกับ IP Address และ Port Number ที่ Server ได้เปิดรอไว้สำหรับ Data Channel แล้ว Client ก็จะใช้ข้อมูลนั้นในการเริ่มต้นการเชื่อมต่อ Data Channel ไปยัง Server ครับ วิธีนี้มักจะทำงานได้ดีกว่าเมื่อ Client อยู่หลัง Firewall เพราะ Client เป็นฝ่ายเริ่มการเชื่อมต่อออกไปทั้งหมด
ทำให้ผมรู้สึกว่าน่าสนใจที่จะมาลองวิเคราะห์ว่า ทำไม ผู้คนในงาน World Economic Forum ที่จัดที่เมืองดาวอส ประเทศสวิตเซอร์แลนด์ ถึงคิดเช่นนั้นกันะ
เรามาเริ่มที่ทักษะแรกกันเลยยย
Technology Skill
AI and Big Data
ในปัจจุบัน ปัญญาประดิษฐ์ หรือ AI เป็นหนึ่งในเครื่องมือที่ได้รับความนิยมอย่างล้นหลาม ด้วยความสามารถที่ล้นเหลือ สามารถช่วยเราเพิ่มประสิทธิภาพ เพิ่ม productivity และอีกหลายสิ่งที่มาช่วยอำนวยความสะดวกในชีวิตประจำวัน
การมาถึงของ Generative AI เช่น ChatGPT, Google Gemini, X Grok, และ Anthropic Claude ยิ่งทำให้ AI เป็นเหมือนมิตรสหายคู่ใจที่ไม่ว่าจะถามอะไรก็ให้คำตอบได้เสมอ ทำงานจิปาถะได้ทั้งนั้นตั้งแต่วางแผนงานในแต่ละสัปดาห์ไปจนถึงเป็นคนให้คำซัพพอร์ทในช่วงที่รู้สึกเปราะบางเช่นกัน
แต่การที่เราใช้ Gen AI เหล่านี้โดยไม่รู้เทคโนโลยีเบื้องหลัง หรือวิธีการใช้งานมันอย่างละเอียดก็อาจนำมาซึ่งปัญหา (hallucination) หรือ ไม่สามารถดึงประสิทธิภาพของพวกมันได้อย่างเต็มที่นัก
เพราะฉะนั้นหากเรารู้วิธีการใช้มัน รวมไปถึงหลักการพื้นฐานของ AI และ Big Data เรียนรู้วิธีการใช้ Few Shot Prompting,รู้ว่า Model แต่ละชนิดเหมาะสมกับงานแบบไหน รู้ว่า Platform อย่าง make หรือ n8n สามารถใช้ทำงานประเภท automate ได้ ก็จะยิ่งทำให้เราดึงประสิทธิภาพออกมาได้มากขึ้น ทำให้เราเข้าถึงประสบการณ์ที่ขับเคลื่อนด้วย AI ได้ยิ่งขึ้นอีก้ดวย
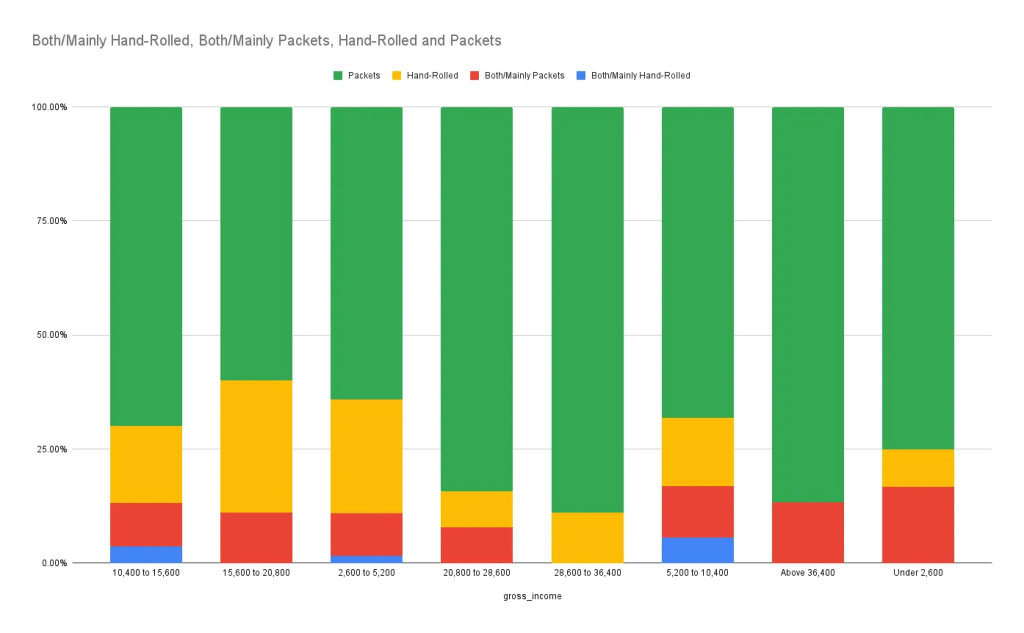
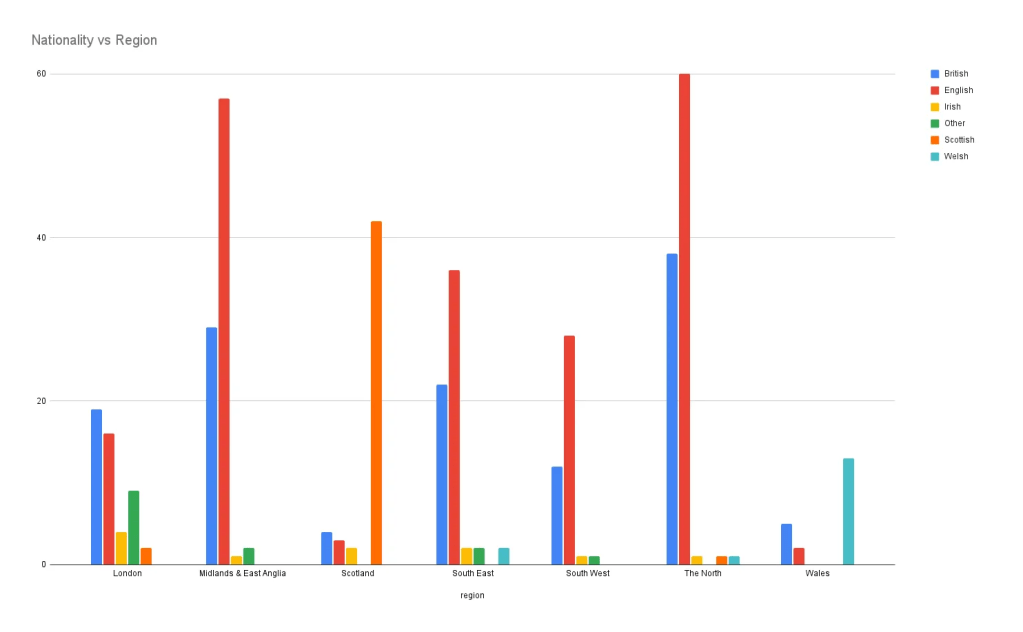
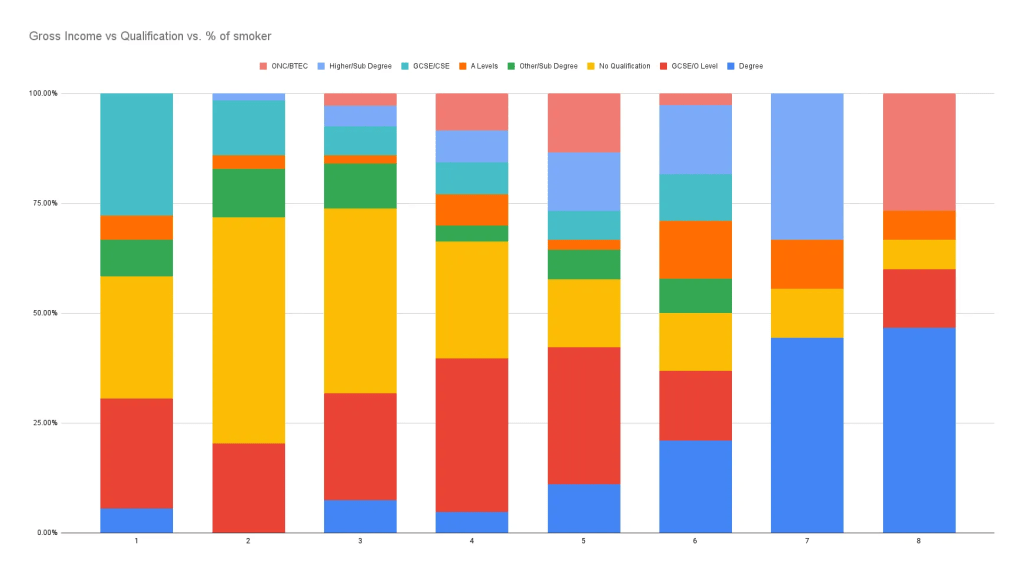
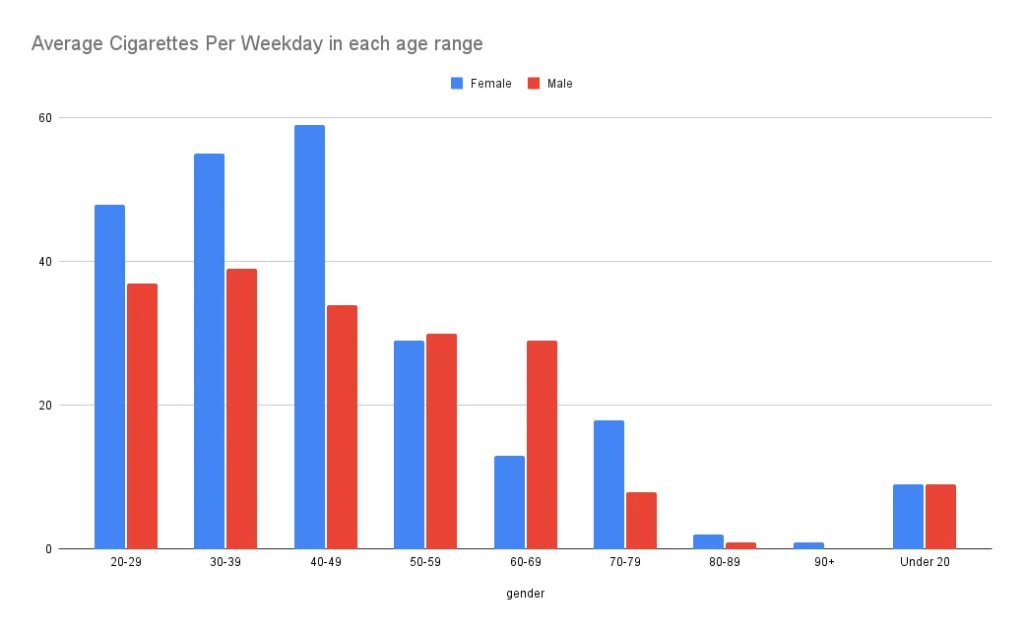
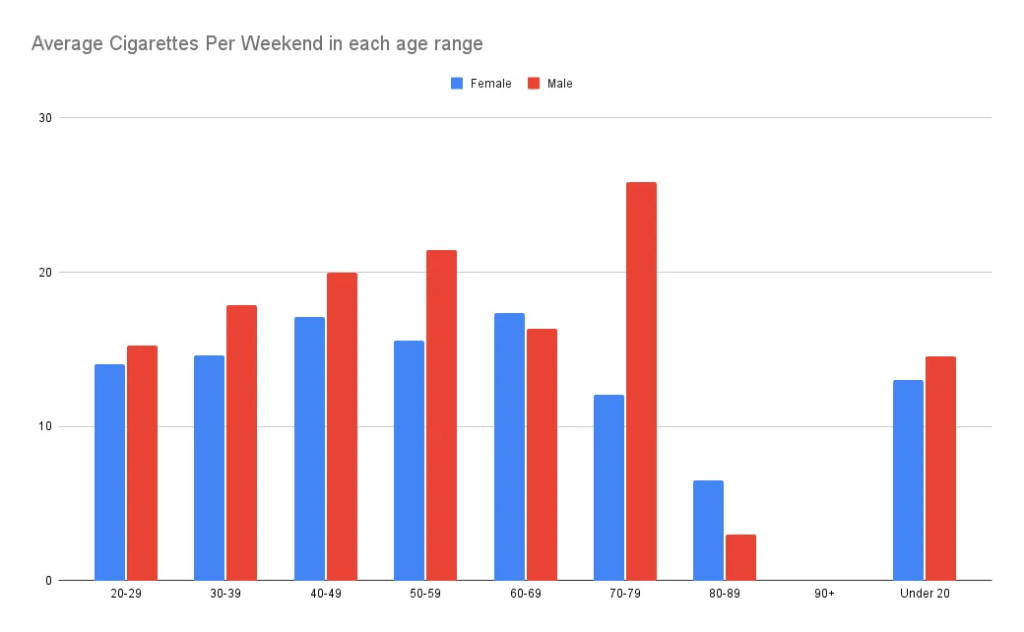
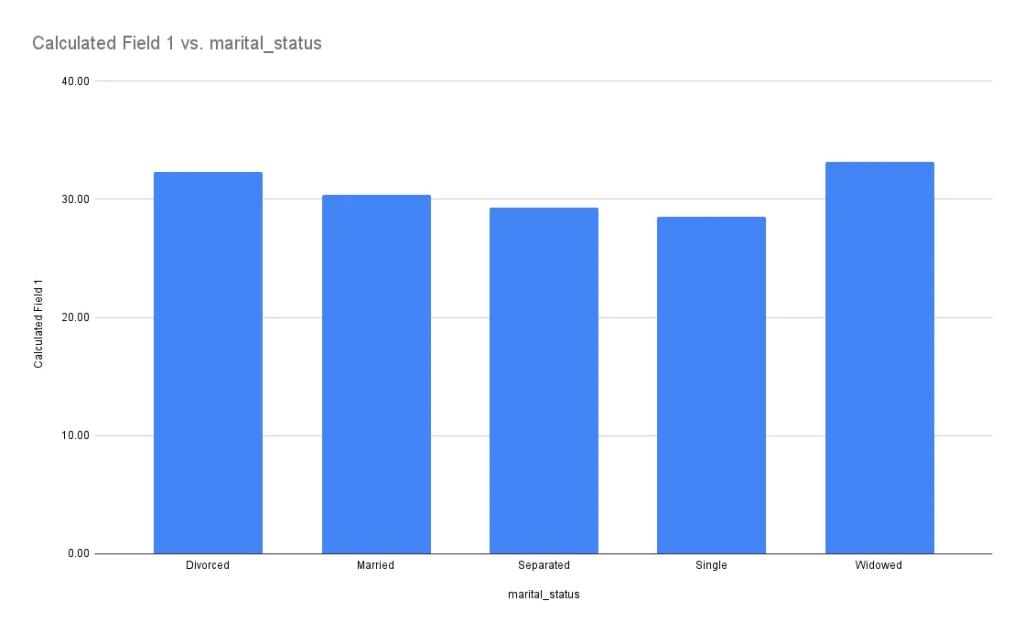
ภายในข้อมูลชุดนี้ ไม่มีการระบุข้อมูลประเภทเวลา (date/time) ทำให้เราไม่สามารถสร้างกราฟประเภท line chart หรือ time series chart ได้
หาก กราฟนี้มีข้อมูลประเภทนี้เพิ่มขึ้นเราสามารถวัดได้ว่าในแต่ละช่วงเวลาของปี ปริมาณบุหรี่ที่สูบแปรผันหรือไม่ หรือ ถ้าข้อมูลเวลายาวนานเพียงพอก็สามารถนำมาตั้งสมมติฐานว่า ในอดีตจนถึงปัจจุบันบุหรี่แต่ละประเภทมีความนิยมต่างกันเช่นไร (multiple line graph in one chart) เป็นต้น


















































{kind=link}