
เป็นเวลาหลายเดือนที่ผมเรียนจบจาก Data Science Bootcamp กับ Ad’ Toy และได้เริ่มเขียน Posts หลายๆอัน หลังจากมัวไต่แรงก์ TFT Set 14 ผมว่ามันถึงเวลาอันสมควรแล้วที่จะเขียน Post เพื่อทบทวนและแชร์ไอเดียเกี่ยวกับ Classical Machine Learning ที่ผมได้เรียนในคอร์สกับ Ad’ Toy
แต่ครั่นจะให้ผมแค่อธิบายสิ่งที่ได้เรียนมาในคอร์สก็ดูจะเบสิคเกินไป ผมจะพาทุกท่านไปดูการทำและวิเคราะห์ไอเดียผ่าน data ใน kaggle แทนเพื่อให้ทุกท่านได้เห็นภาพมากขึ้น
เนื้อหาส่วนนี้จะแบ่งออกเป็น 4 พาร์ทเพื่อไม่ให้ยาวเกินไปนะครับ
โดยในส่วนของ Main Series นั้นเราจะโฟกัสไปที่การแตะๆ Walkthrough เนื้อหาภาพรวมกันเสียก่อน แล้วเดี๋ยวเราค่อยมาเจาะลึกกันสำหรับแต่ละ Algorithms ใน Series ถัด
Table of Content
- Introduction: Why does classical machine learning matter ?
- Linear Regression
- Dataset & How we preprocess data
- Simple Linear Regression
- Train & Validate
- Multi-variable Linear Regression
- No Free Lunch
- Conclusion & Evaluation
- Sourcecode
- References
Introduction: Why Classical Machine Learning Matters ?
ในยุคที่ปัญญาประดิษฐ์ ( AI ) กลายเป็นส่วนหนึ่งของการดำรงชีวิต ทั้งในด้านการเพิ่มประสิทธิภาพและคุณภาพของงาน ไปจนถึงการทดแทนแรงงานมนุษย์ในหลายภาคส่วน
ความเข้าใจในรากฐานของเทคโนโลยีเหล่านี้ โดยเฉพาะ Machine Learning (ML) จึงเป็นสิ่งสำคัญอย่างมาก
การเรียนรู้ Classical Machine Learning ไม่เพียงช่วยให้เรามองเห็นเบื้องหลังการทำงานของระบบอัจฉริยะ แต่ยังเป็นจุดเริ่มต้นที่แข็งแกร่งในการต่อยอดสู่เทคโนโลยีสมัยใหม่อย่าง Deep Learning และ Generative AI เช่นกัน
แล้ว Machine Learning คืออะไร? โดยพื้นฐานแล้ว Machine Learning คือศาสตร์แขนงหนึ่งของวิทยาการคอมพิวเตอร์ที่เกี่ยวข้องกับการทำให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลได้เอง
โดยไม่จำเป็นต้องถูกโปรแกรมให้ทำงานแบบชัดเจนในทุกขั้นตอน เมื่อทำการสอนเสร็จแล้ว เราก็จะได้ Model ในรูปแบบสมการ หรือไม่เป็นรูปแบบสมการที่ใช้ในการทำนาย การจัดกลุ่มและอื่นๆได้อีกเช่นกัน

สำหรับ Machine Learning แล้วก็จะแบ่งเป็น Classic และ Modern โดยเราจะโฟกัสไปที่ Classic กันก่อน
สำหรับ Classical Machine Learning นั้นสามารถแบ่งเป็น 2 กลุ่มใหญ่ๆได้แก่
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
เป็นวิธีการสอนรูปแบบหนึ่งที่เราจะให้คอมพิวเตอร์เรียนรู้จากข้อมูลที่มีหัวตาราง (labeled data) โดยประกอบไปด้วย 2 รูปแบบได้แก่
- Regression
- Classification
Unsupervised Learning
อีกหนึ่งวิธีการสอนที่จะให้ data แบบไม่มี metadata เพื่อหารูปแบบ หรือสรุปข้อมูลออกมา โดยรุปแบบการเรียนรู้นี้จะนิยมใช้เทคนิค Clustering และ Principal Component Analysis หรือ PCA
Reinforcement Learning
รุปแบการสอนที่เน้นให้ Agent หรือตัวโมเดลสำรวจ สภาพแวดล้อม environment และเลือกกระทำการใดๆต่าง Action โดยที่การกระทำเหล่านั้นจะมีผลลัพธ์ตามมาไม่ว่าจะเป็ฯ รางวัล Reward หรือ บทลงโทษ Penalty
การสอนรูปแบบนี้มีวัตถุประสงค์เพื่อให้ Agent นั้น ได้รับรางวัลมากที่สุด หรือ ได้รับบทลงโทษน้อยที่สุด โดยโมเดลที่มีชื่อเสียงผ่านการสอนด้วยวิธีนี้ก็จะมี AlphaGo เป็นตัวอย่าง
ในบทความนี้ผมจะพูดถึงแค่ 1 ใน รูปแบบของ Supervised Learning นั้นคือการทำ Linear Regression เสียก่อน เพื่อไม่ให้ยาวจนเกินไปนะครับ เกริ่นกันมามากพอละ ป่ะลุยกั๊นนนนน
Linear Regression
ก่อนที่เราจะไปพูดถึง Linear Regression นั้นเราควรเข้าใจกับคำว่า สหสัมพันธ์ (Correlation) เสียก่อน
Correlation เป็นการวัดความสัมพันธ์เชิงเส้นตรงระหว่างตัวแปรสองตัว โดยจะมีค่าอยู่ระหว่าง [-1,1] เท่านั้น
Correlation บอกได้แค่ตัวแปรสองตัวนี้มีความสัมพันธ์กันระดับไหน วัดออกมาเป็นตัวเลขระหว่าง [-1, +1] เครื่องหมายบวกลบบอกทิศทางความสัมพันธ์ของตัวแปร ถ้าไม่มีความสัมพันธ์เลย correlation จะเท่ากับศูนย์ (หรือประมาณ +/- 0.1)
Linear Regression เป็นสมการ หรือโมเดลรูปแบบนึงที่ใช้ประเมินคุณภาพของความสัมพันธ์ (relationship) โดยมักจะมาในรูปแบบ สมการเส้นต้น หรือ สมการหลายตัวแปร
y = mx + b
หรือ
y = b0 + b1*x1 + b2*x2 + b3*x3 + .. + bk*xk
โดย algorithm นี้จะเป็น Alogirthm ที่เหมาะสมก็ต่อเมื่อง error ที่เกิดขึ้นรอบๆ เส้นตรงดังกล่าวต่ำนั้นเอง
Linear Regression เหมือนเป็น add-on ต่อยอดจากการหาค่า Correlation ว่าถ้าตัวแปร x เปลี่ยนเท่านี้ตัวแปร y จะ เปลี่ยนไปเท่าไหร่นั้นเอง
ตัว m ในสมการเราจะเรียกว่า Regression Coefficient และ b คือ Interception point
Dataset & How We Preprocess Data
สำหรับ ตัวอย่างนี้ผมจะใช้ dataset ที่ชื่อว่า AirQualityUCI นะครับสามารถคลิกลิ้งค์ตรงนี้เพื่อเข้าไปหาต้นทางได้เลย
ก่อนโหลด dataset เราก็ต้องทำความเข้าใจแต่ละ Columns ก่อนว่าคืออะไรกันบ้างครับ
| Feature | Description |
|---|---|
| Date | วันที่วัดค่า |
| Time | เวลาที่วัดค่า |
| CO(GT) | ความเข้มข้นของ Carbon Monoxide ในหน่วย (µg/m³). |
| PT08.S1(CO) | ค่าที่ได้จากการวัด Carbon Monoxide จากเครื่องวัด |
| NMHC(GT) | ความเข้มข้นของ non-methane hydrocarbons (NMHC) (µg/m³). |
| C6H6(GT) | ความเข้มข้นของ benzene (C6H6) in the air (µg/m³). |
| PT08.S2(NMHC) | ค่าที่ได้จากการวัด non-methane hydrocarbons (NMHC) จากเครื่องวัด |
| NOx(GT) | ความเข้มข้นของ nitrogen oxides (NOx) in the air (µg/m³). |
| PT08.S3(NOx) | ค่าที่ได้จากการวัด NOx จากเครื่องวัด |
| NO2(GT) | ความเข้มข้นของ nitrogen dioxide (NO2) in the air (µg/m³). |
df=pd.read_csv(filepath_or_buffer='AirQualityUCI.csv', sep=',', decimal=',', header=0)
เนื่องจากไฟล์ต้นทางเป็นไฟล์ .csv เพราะฉะนั้นเราก็เรียกใช้ method .read_csv จาก library pandas เพื่อใช้อ่านโดยกำหนค่าตาม filepath (ให้ง่ายก็ลากไฟล์ที่จะอ่านมาไว้โฟลเดอร์เดียวกัน) และกำหนด separator (อักขระทีใช้ในการแบ่งข้อมูลใน csv ) และ decimal (อักขระที่ใช้แทนจุดทศนิยม) โดยกำหนดให้ header อยู่ที่แถว 0
เมื่ออ่านค่าได้แล้วเราก็มาดูข้อมูลคร่าวๆกันเถอะ
df.head() และ df.describe()

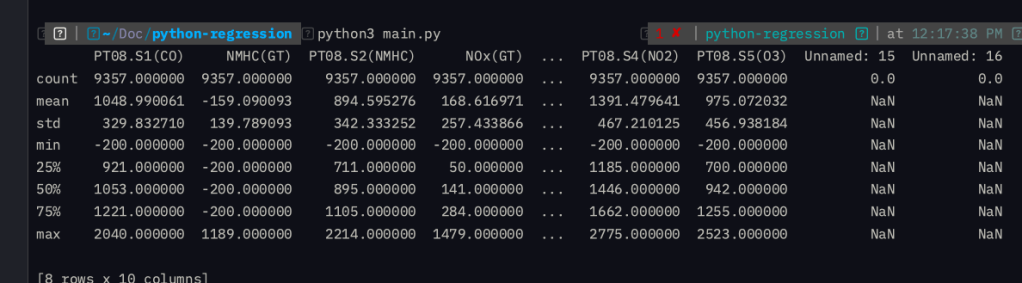
จากตัวอย่างหัวตารางจะเห็นได้ว่าข้อมูลนี้จะเกี่ยวกับการวัดคุณภาพอากาศที่เก็บได้เป็นระยะเวลา 1 ปี 1 เดือนนะครับ โดยมีวัตถุประสงค์เพื่อใช้ในการทำ model สำหรับการทำนายและวิเคราะห์ข้อมูลภายในงานด้าน วิทยาศาสตร์สิ่งแวดล้อมและสุขภาพอนามัย
ในข้อมูลจะเห็นว่ามี 2 Columns ที่ไม่มีชื่อใช่ไหมครับ เพราะฉะนั้นเราก็ต้อง Drop 2 Columns นั้นออกด้วยคำสั่งด้านล่าง
df = df.loc[:, ~df.columns.str.contains("^Unnamed")]
คำสั่ง loc ใน pandas หมายถึงการเข้าถึงข้อมูลใน DataFrame โดยอาศัยการกำหนด rows หรือ columns หรือจะใช้ค่า boolean arrays ก็ได้เช่นกัน
จากคำอธิบาย Dataset ใน Kaggle ได้บอกว่าบางค่าในแต่ละเดือนก็ไม่สามารถบันทึกได้เขาก็เลยใส่ -200 มาเพราะฉะนั้นเราก็ต้องลบออกเช่นกัน
df = df.replace(-200,np.nan).dropna()
ก็คือผมเปลี่ยน -200 ทั้งหมดให้เป็น np.nan ก่อนแล้วก็ค่อย drop NaN ทิ้ง
โอเคเราได้ทำการ clean data เรียบร้อยแล้ว ในขั้นตอนถัดไปเราก็สามาถนำข้อมูลนี้ไปใช้ train ได้แล้วครับ
Simple Linear Regression
จากข้อมูลผมจะทำการเริ่มจากใช้ ตัวแปรตัวเดียวเพื่อหาความสัมพันธ์ของข้อมูลก่อน ในกรณีนี้จะเลือก y เป็น NMHC และ x เป็น C6H6(GT)
y = np.array(df['NMHC(GT)']).reshape(-1,1)
และ
X = np.array(df['C6H6(GT)']).reshape(-1,1)
Split Data
เมื่อได้ X และ y เป็นที่เรียบร้อยแล้วเราก็นำข้อมูลดังกล่าวมา split โดยผลแบ่งเป็น ใช้ฝึก 80% และ ใช้ทดสอบ 20% และสาเหตุที่ใส่ค่า random_state = 42 เพราะว่าจะให้ได้ผลลัพธ์การสุ่มแบ่งข้อมูลเหมือนเดิมในทุกๆครั้ง
X_trained, X_test, y_trained, y_test = train_test_split(X, y,train_size=0.8, test_size=0.2, random_state=42)
Train and Validate
หลังจากนั้นเราก็จะนำ data ที่แบ่งมา train กัน
lnr = LinearRegression()
lnr.fit(X_trained, y_trained)
y_pred = lnr.predict(X_test)
- สร้างฟังก์ชั่น linear regression ด้วยฟังก์ชั่น LinearRegression
- นำ data X_trained และ y_trained มา train
- ทำนายค่า X_test ด้วย predict()
จากนั้นก็ทำการหาค่า metrics ต่างๆ
print("Mean Absolute Error Trained ", mean_absolute_error(y_trained, y_trained_pred))
print("Mean Absolute Error Test ", mean_absolute_error(y_test, y_pred))
จะได้ผลลัพธ์ดังนี้
# Mean Absolute Error Trained 61.831639475521364
# Mean Absolute Error Test 60.9002976731785หน่วยที่ใช้วัดจะเป็นหน่วย µg/m³ ไมโครกรัม ต่อ ลูกบาศก์เมตร หากดูจากค่า trained MAE และ test MAE นั้นถือว่ามีค่าใกล้กันแต่แปลว่า model เราค่อนข้าง generalised
อย่างไรก็ตาม MAE เป็นค่าที่ยิ่งใกล้ 0 จะยิ่งให้ผลลัพธ์ที่ดีเพราะแปลว่าเราอ่านค่าคลาดเคลื่อนน้อย แต่นี้ MAE ตั้ง 60 แปลว่า simple linear regression model ไม่ตอบโจทย์กับ dataset นี้
เพราะฉะนั้นเรามาลองหาค่าใหม่แต่ใช้เป็น multi-varaible linear regression กันอีกรอบ
Multi-variable Linear Regression
y = np.array(df['NMHC(GT)']).reshape(-1,1)
df_pollutant = df[['PT08.S2(NMHC)', 'C6H6(GT)','T', 'RH', 'AH', 'NO2(GT)', 'NOx(GT)', 'CO(GT)']]
X = np.array(df_pollutant).reshape(-1, len(df_pollutant.columns))
X_trained, X_test, y_trained, y_test = train_test_split(X, y,train_size=0.8, test_size=0.2, random_state=42)
lnr = LinearRegression()
lnr.fit(X_trained, y_trained)
y_pred = lnr.predict(X_test)
y_trained_pred = lnr.predict(X_trained)
print("Mean Absolute Error Trained ", mean_absolute_error(y_trained, y_trained_pred))
print("Mean Absolute Error Test ", mean_absolute_error(y_test, y_pred))
เราก็ได้ผลลัพธ์ดังนี้
# Mean Absolute Error Trained 59.31405073871236
# Mean Absolute Error Test 57.858497022746086สังเกตว่า แม้เราจะเพิ่มตัวแปรเข้าไปเป็นจำนวนมากแต่ค่า MAE กับลดลงเพียง 2-3 µg/m³ เท่านั้นเอง ซึ่งก็ยังคลาดเคลื่อนเยอะมาก
ลองจินตนาการว่าค่าที่แท้จริงได้ 7 µg/m³ แต่ดันอ่านได้ 64-66 µg/m³ ดูสิครับทำนายกันผิดผลาดแน่นอน
No Free Lunch
จากตัวอย่างข้างต้นทำให้เราได้ข้อสรุปว่าการที่เราจะ train model อะไรซักอย่างนั้นจะต้องลองหลายๆ model เพื่อหา model ที่ดีที่สุดทั้งในเรื่องของเวลาและค่าใช้จ่าย
ซึ่งนี้เป็นไปตามหลักการที่ว่า ไม่มีโมเดลไหนเก่งที่สุด และสามารถตอบโจทย์ได้ทุกปัญหา หรือ No Free Lunch บางทีอาจจะมีโมเดลอื่นอย่าง Decision Tree, Random Forest และ อื่นๆ ที่จะสามารถนำ data นี้ไปทำนายได้อย่างมีประสิทธิภาพมากขึ้นไปอีกได้เช่นกัน
Conclusion & Evaluation
สรุป dataset นี้ไม่เหมาะที่จะใช้ Linear Regression model ในการทำนายค่าเนื่องจากว่ามีผลลัพธ์ที่ไม่น่าพึ่งพอใจและเสี่ยงตอนความคลาดเคลื่อนสูง
แม้ว่าจะมีกาารเพิ่มตัวแปรเข้าไปแล้วก็ตาม ทั้งนี้ dataset นี้อาจเหมาะกับโมเดลอื่นๆมากกว่า
จากที่ ผมลองดูมา dataset ใน kaggle ที่ดูแล้วน่าจะใช้ Linear Regression ได้ก็น่าจะเป็น California Housing Price ครับเพื่อนๆก็สามารถลอง ขั้นตอน cleansing data (preprocessing) บวกกับ การสร้าง Linear Regression Model ที่ผมเขียนไปลองดูกันได้ ลองแล้วได้อย่างไรก็อย่าลืมมาแชร์กันนะครับ

แล้วเพื่อนๆ เคยเจอโปรจคไหนที่มีปัญหา No Free Lunch อย่างนี้ไหมครับ
Sourcecode
https://gist.github.com/patrawi/4af831586d73e492362cb2a19148f79d.jsReferences
# ทำความรู้จัก “Linear Regression” Algorithm ที่คนทำ Machine Learning ยังไงก็ต้องได้ใช้!
# ทำนายราคาบ้าน Boston ด้วย Linear Regression
