
Table of Content
- ความลำบากในงานสายข้อมูล เมื่อข้อมูลของเราอยู่ในรูปแบบ PDF
- เสาะหาซึ่งวิธีการในการโหลดข้อมูลและการมาถึงข้อ Google AI Studio
- ช่วงของการลองผิดลองถูกการประยุกต์ใช้ Google AI Studio เพื่อการอ่าน PDF
- ผู้อยู่เบื้องหลังทุกสิ่ง อธิบายเกี่ยวกับ Gemini 2.5 Flash Model
- เหนือยิ่งกว่าปัจจุบัน การนำความรู้ไปประยุกต์ใช้และพัฒนาต่อ
ความลำบากในงานสายข้อมูล เมื่อข้อมูลของเราอยู่ในรูปแบบกระดาษ
ตั้งแต่อดีตจนถึงปัจจุบัน นักวิทยาศาสตร์ข้อมูล หรือ Data Scienctist ล้วนแล้วแต่ต้องเคยเจอปัญหาที่ว่าข้อมูลนั้นอยู่ในรูปกายภาพ(physical) แทนที่จะเป็นลักษณะดิจิตอล (digital)
ซึ่งข้อมูลเหล่านี้สร้างความรำคาญให้แก่พวกเขาเป็นอย่างมาก ในอดีต ก่อนที่จะมีนวัตกรรมอย่าง OCR (Optical Character Recognition) ที่เกิดจากการประยุกต์ใช้ Machine Learning เหล่า Data Scientist ต้องรับมือกับข้อมูลกายภาพด้วยการคีย์ข้อมูลด้วยมือ ไม่ว่าจะผ่านหน้าจอ Console, Web Application หรือ GUI ต่างๆ
วิธีดังกล่าวนั้นมีโอกาสเกิด Human Error เป็นอย่างสูง ลองจินตนาการดูสิ คุณกำลังนั่งกรอกข้อมูลเหล่านี้ประมาณ ตี 2-3 อดหลับอดนอน นั่งกรอกตารางข้อมูลเหล่านี้มากกว่า 100 หน้ามาแล้ว 3 วัน

ซึ่งมันแทบจะเป็นไปไม่ได้เลยที่คุณจะกรอกโดยไม่ผิด และเมื่อกรอกเสร็จคุณก็ต้องมาเสียเวลานั่งแก้ข้อมูลเหล่านี้ เสียทั้งเวลา เสียทั้งค่าใช้จ่าย และอื่นๆที่จะตามมาอีกมากมาย
ความยุ่งยากในการนำเข้าข้อมูลนี้ ทำให้หลายคนเลือกที่จะละทิ้งข้อมูลไปอย่างน่าเสียดาย เพราะมองว่ายากเกินกว่าจะนำไปใช้ประโยชน์ได้ สุดท้ายข้อมูลอันมีค่าเหล่านี้ก็กลายเป็นเพียง ‘ขยะดิจิทัล’ ที่ไม่มีใครสามารถนำไปประยุกต์ใช้ได้เลย
แล้วถ้าเกิดว่าวันนึง มันดันมีเทคโนโลยีที่สามารถแก้ปัญหาตรงนี้ได้ละ เทคโนโลยีที่จะช่วยให้เราสแกนเอกสารและทำออกมาเป็นไฟล์พร้อมนำเข้าข้อมูล บนโปรแกรต่างๆไม่ว่าจะเป็น Spreadsheet, Excel หรือ โปรแกรมจากการเขียนโค้ดอย่าง python หรือ R คุณลองคิดดูสิว่าขยะเหล่านี้จะมีค่าแค่ไหน ? เพราะฉะนั้น วันนี้ผมจะพาทุกท่านมารู้จักกับ AI จากทาง Google อย่าง Gemini Flash 2.5 ที่เราสามารถทดสอบ บนGoogle AI Studio ซึ่งจะเข้ามาช่วยแก้ปัญหาและอุด Pain Point นี้กันครับ
เสาะหาซึ่งหนทาง: การมาถึงของ Google AI Studio
ในช่วงแรกที่เหล่า Data Scientists ต้องแก้ปัญหานี้ พวกเขาก็พยายามค้นหาวิธีการต่างๆ อาทิเช่น การ Scan ข้อมูลเหล่านั้นเป็น PDF Copy/Paste บ้างละ ใช้โปรแกรม online สำหรับแปลง PDF ไปเป็น CSV บ้างละ ไปจนถึงขั้นยอมเสียเงินจำนวนมากเพื่อซื้อโปรแกรมมาปิดจุดอ่อนนี้
วิธีเหล่านั้นล้วนสามารถแก้ปัญหาขั้นเบื้องต้นได้แต่ก็มีจุดอ่อนในตัวเช่นกัน เช่นการ Copy/Paste นั้นในระยะยาวนั้นจะไม่เป็นผลดีต่อเวลาเป็นอย่างมาก การใช้โปรแกรมออนไลน์ก็ดูเป็นวิธีที่เวิร์ค แต่ถ้าเกิดมีไฟล์เป็นจำนวนมากก็คงจะไม่ไหว และการใช้ซอฟแวร์สำเร็จรุปนั้นก็อาจจะให้ผลลัพธ์ที่ไม่ดีหากข้อมูลของเรานั้นซับซ้อน
ด้วยการมาถึงของยุคที่ Generative AI เป็นที่รู้จักแพร่หลาย บริษัท Google ก็ไม่น้อยหน้าปล่อย แพลทฟอร์ม ออกมาให้ผู้ใช้งานอย่างเราๆได้ทดลองใช้ฟรี โดยเราสามารถเข้าไปลองเล่น Model ต่างๆของทาง Google ผ่านทาง Google AI Studio
ทำไมต้อง Google AI Studio ทั้งๆ ที่เจ้าอื่นก็มีแพลตฟอร์มทดลองให้ใช้เหมือนกัน? คำตอบง่ายๆ คือ ‘เพราะมันฟรี’ ผู้ใช้งาน Gemini เวอร์ชั่นปกติอาจเข้าถึงได้แค่ Gemini Flash แต่ใน Google AI Studio คุณสามารถใช้งาน Gemini Pro ได้ฟรีไม่จำกัด นี่คือข้อได้เปรียบสำคัญที่ไม่อาจมองข้าม
แถมเรายังสามารถปรับแต่งค่าต่างๆเพื่อให้ AI ตอบคำถามตามความต้องการของเราได้ เช่น ตั้งค่า Temperature ต่ำ หรือ สูง เพื่อกำหนดความสร้างสรรค์ของ AI กำหนด output length ว่าจะให้ตอบได้ไม่เกินครั้งละเท่าไหร่ ไปจนถึงการกำหนด Top P เพื่อควบคุมความหลากหลายของคำตอบ โดยให้ AI เลือกจากกลุ่มคำที่มีความน่าจะเป็นสูงสุด
อีกหนึ่งสิ่งที่ น่าประทับใจมากๆของ Google AI Studio ก็คือจำนวน Context window ที่ให้มาอย่างจุใจถึง 1 ล้าน ส่งผลให้การคุยของผู้ใช้งานนั้นราบรื่นอย่างไร้ปัญหา และด้วยเหตุนี้ Google AI Studio จึงเหมาะมากที่เราจะใช้เพื่อ POC concept ของเราสำหรับประยุกต์ใช้ในอนาคตนั้นเอง
ช่วงของการลองผิดลองถูกการประยุกต์ใช้ Google AI Studio เพื่อการอ่าน PDF
สำหรับจุดประสงค์ในการทำครั้งนี้ก็คือการที่เราสามารถอ่านไฟล์สแกน PDF ได้เป็นจำนวนมากเพื่อที่จะดึงข้อมูลจากกระดาษออกมาและ insert เข้าฐานข้อมูล
ด้วยเหตุนี้ เพื่อให้ได้มาซึ่ง tools ที่ตอบโจทย์เรามากที่สุด จึงมีความจำเป็นว่าเราต้องทดลองใช้ Model ที่กูเกิ้ลมีนั้นมาทดสอบเสียก่อน โดยในเคสนี้เราจะทดสอบด้วยโมเดล 2.5 Flash และ 2.5 Pro
ความแตกต่างระหว่าง Pro Model & Flash Model
Pro Model – เป็น โมเดลที่ถูกสร้างมาสำหรับการคิดอย่างเป็นตรรกะ (reasoning), การโค้ดดิ้ง (Coding) และความเข้าใจในหลากหลายมิติ ( Multimodal understanding ) เพื่อใช้ในการคิดวิเคราะห์ปัญหาที่ซับซ้อน ส่งผลให้มีค่า Latency ที่สูงเพราะ Model จำเป็นต้องคิดไปทีละ Step ก่อนที่จะได้รับคำตอบ
Flash Model – สำหรับ Flash Model นั้นถูกออกแบบมาให้ใช้กับงานประมวลผลเป็นจำนวนมากเช่น ไฟล์ PDF หลายๆไฟล์ งานที่ต้องการ latency ตำ่และรับ input ได้เยอะ, หรือ agentic use cases
จากข้อมูลข้างต้นเราจึงควรเลือกใช้ Flash Model เพราะด้วยความที่ Latency ต่ำ + กับเหมาะทำงานซ้ำๆ ถือว่าตอบโจทย์ของเราเป็นอย่างมาก
หลังจากที่เลือก Model เรียบร้อยแล้วเรามาดูขั้นตอนในการทำงานก่อนดีกว่า
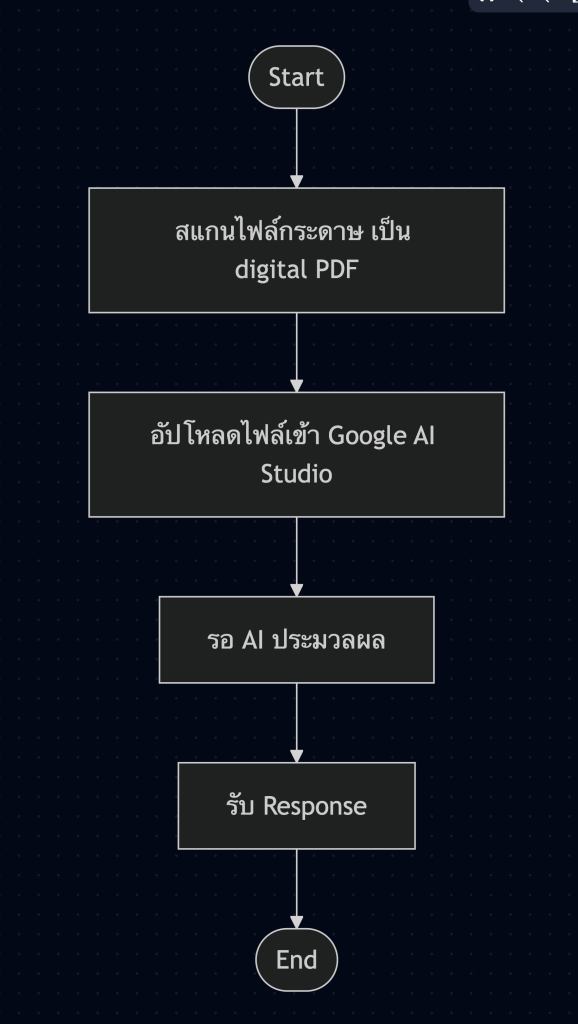
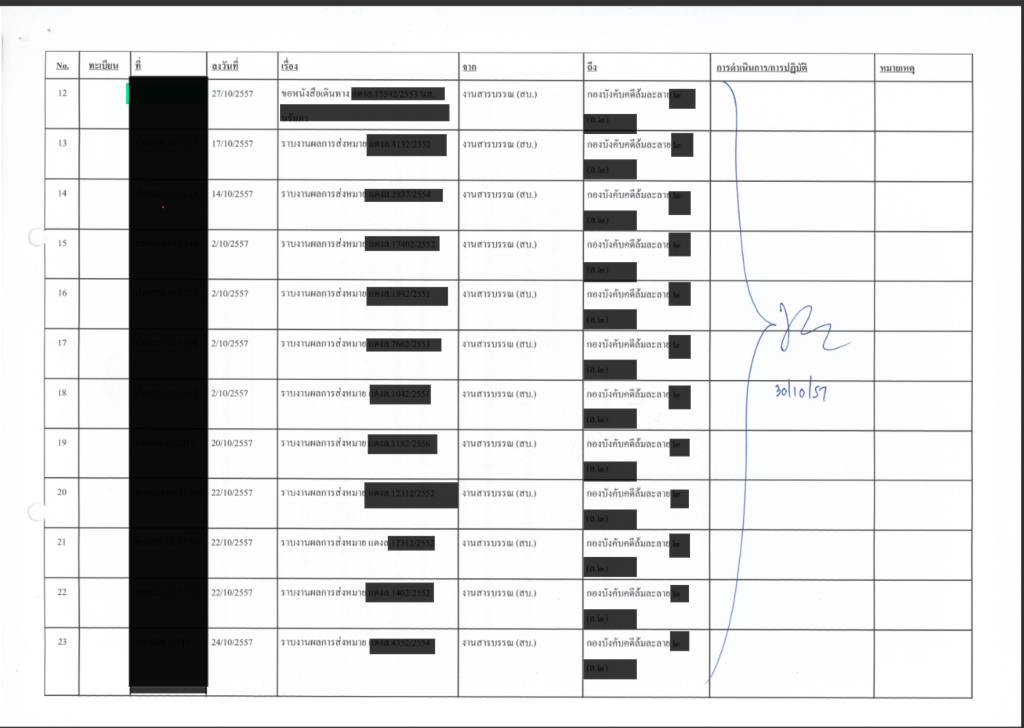
จาก Flowchart ข้างต้นในขั้นตอนแรกนั้นเราต้องสแกนเอกสารก่อนและข้างล่างนี้ก็คือเอกสารที่เราต้องการอ่านนั้นเอง
ใน ช่วง Proof cf Concept นั้น เราไม่จำเป็นที่จะต้องใช้ API_KEY โดยเราสามารถ Log in Gmail และใช้งานบน แพลทฟอร์ม Google AI Studio ได้เลย

จากนั้นทำการอัพโหลดรูปภาพเข้าไป และพิมพ์ System Instruction ดังนี้
Extract data into CSV format where | separates columns. Use this exact column order:
{'|'.join(CSV_COLUMNS)}.
Rules:
1. Keep f1 always 0.
1.1 Always keep {NUM_COLUMNS} columns
2. Extract doc_no as the second column and F as the fourth. Do not swap these.
3. Blank fields must contain 0.
4. If which row you can't understand skip it.
Example:
{'|'.join(CSV_COLUMNS)}
1|0000/2559|0|1/7/2559|รายงานการสำรองข้อมูลประจำเดือน มิย.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|เดินเรื่องเอง เดินเรื่องเอง|0
2|กบ0000/1222|0|30/6/2559|ขอส่งเงินค่าไฟฟ้าที่พักอาศัยเจ้าหน้าที่ ประจำเดือน พค.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|0|0
Always make it {NUM_COLUMNS} columns
Ensure the output always aligns exactly to this structure.จากนั้นทำการกด Run และรอผลัพธ์
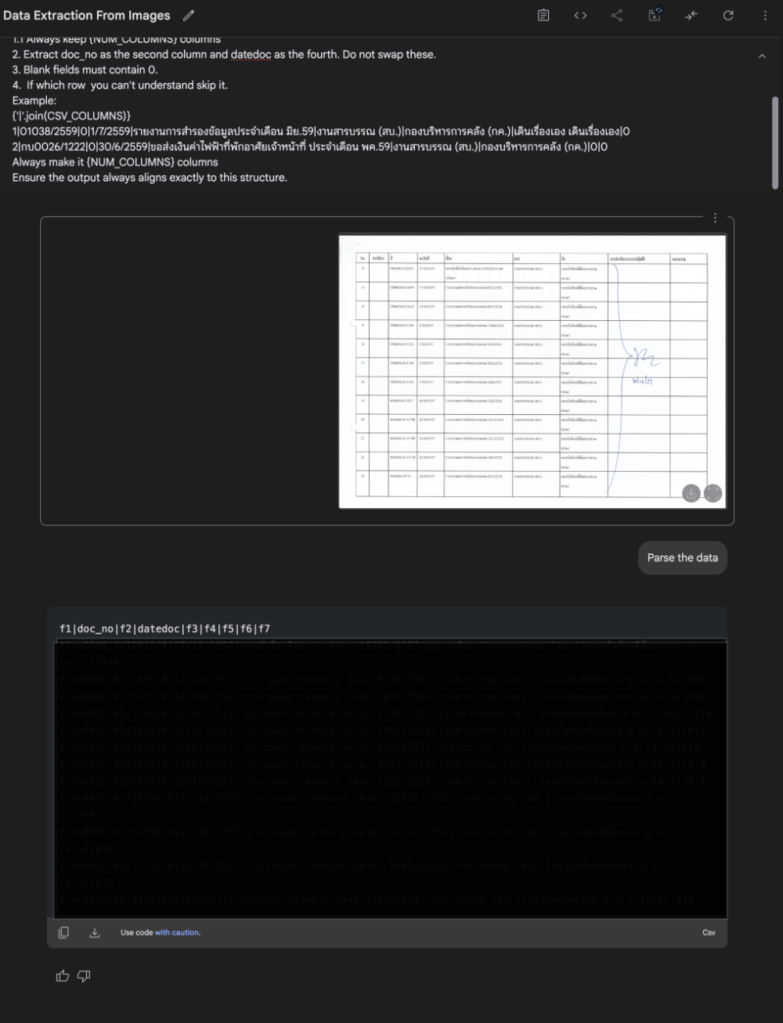
จะเห็นได้ว่าเราได้ข้อมูลในรูปแบบ CSV พร้อมนำไปใช้ในขั้นตอนต่อไปได้ทันที! แต่หากเราไม่ได้กำหนด System Instruction หรือ Prompt ที่ชัดเจนและรัดกุมแล้วละก็ เราอาจได้ข้อมูลในรูปแบบที่ไม่ใช่ CSV หรือได้ Format ที่ไม่น่าพึงพอใจ เพราะฉะนั้น ‘หลักการ Prompt Engineering’ จึงสำคัญอย่างยิ่งมากในการดึงศักยภาพของ AI ออกมาใช้ได้อย่างเต็มที่.
ผู้อยู่เบื้องหลังทุกสิ่ง อธิบายเกี่ยวกับ Gemini 2.5 Flash Model
สิ่งที่ใช้ในการคำนวณและวิเคราะห์เอกสาร PDF เหล่านี้ แท้จริงแล้วก็คือ โมเดลภาษาขนาดใหญ่ (LLM) อย่าง Gemini ที่ทำหน้าที่หลักในการแปลงข้อมูลจากไฟล์ให้มาเป็น CSV ตาม Prompt ที่เรากำหนด
อย่างไรก็ตาม กว่าที่จะมาเป็น CSV อย่างที่เราเห็นนั้น ตัว Google AI Studio ก็ต้องแปลงไฟล์แนบในรูป PDF ให้ AI ‘เข้าใจ’ ได้ก่อน
โดยในขั้นแรก ระบบจะทำการตรวจสอบว่า Input ที่ส่งมาเป็นไฟล์แนบ (เช่น PDF หรือรูปภาพ) หรือไม่ ถ้าใช่ ระบบจะส่งไฟล์นั้นไปประมวลผลด้วย OCR (Optical Character Recognition) ก่อน กระบวนการ OCR นี้จะแปลงภาพของตัวอักษรใน PDF ให้กลายเป็น ข้อความดิจิทัล (Text) ที่คอมพิวเตอร์อ่านได้
จากนั้น ข้อความดิจิทัลที่ได้จะถูกนำเข้าสู่กระบวนการ Tokenization ซึ่งเป็นการแบ่งข้อความยาวๆ ออกเป็นหน่วยย่อยๆ ที่เรียกว่า ‘โทเคน (Tokens)’ (เช่น คำ, ส่วนของคำ, หรือเครื่องหมายวรรคตอน)
ต่อมา โทเคนเหล่านี้จะถูกแปลงไปสู่รูปแบบที่ AI สามารถประมวลผลได้ ซึ่งก็คือ ‘Embedding’ ครับ พูดง่ายๆ คือ Embedding คือการแปลงโทเคนแต่ละหน่วยให้เป็นตัวเลขเวกเตอร์ ซึ่งเป็นชุดตัวเลขที่แสดงถึงความหมายและความสัมพันธ์ของโทเคนนั้นๆ ในเชิงคณิตศาสตร์ ทำให้ AI สามารถเข้าใจ และ วัดความใกล้เคียง ของความหมายระหว่างคำต่างๆ ได้
หลังจากนั้น ข้อมูลที่เป็นตัวเลขเวกเตอร์ (Embeddings) เหล่านี้จะถูกส่งเข้าสู่ โมเดล AI ซึ่งโดยทั่วไป จะประกอบด้วยส่วนหลักๆ คือ Encoder และ Decoder
- Encoder ทำหน้าที่ประมวลผล Input (ในที่นี้คือ Embeddings ของข้อความจาก PDF) เพื่อสร้างความเข้าใจบริบทและความหมายทั้งหมดของข้อความนั้นๆ
- Decoder จะใช้ความเข้าใจที่ได้จาก Encoder และคำสั่งจาก Prompt ของเรา (เช่น แปลงเป็น CSV) เพื่อสร้าง Output ออกมาเป็นลำดับของโทเคน ซึ่งต่อมาจะถูกแปลงกลับเป็นข้อความในรูปแบบที่เราต้องการหรือข้อความที่มนุษย์อ่านได้ (เช่น CSV) นั่นเอง
ทุกสิ่งทุกอย่างข้างต้นนั้นล้วนเกิดจากข้อมูลมหาศาลที่โมเดลได้รับการเรียนรู้มาแล้วล่วงหน้า ผสมผสานกับวิธีทางคณิตศาสตร์ที่ซับซ้อน ส่งผลให้ AI สามารถวิเคราะห์และคาดเดาได้อย่างแม่นยำว่าข้อมูลที่อยู่บน PDF เหล่านั้นคืออะไร และควรจะจัดเรียงออกมาในรูปแบบใด
พูดกันมาขนาดนี้แล้ว ละ OCR คืออะไร? OCR (Optical Character Recognition) คือหนึ่งในกระบวนการสำคัญของ Machine Learning ที่ทำหน้าที่แปลง รูปภาพของตัวอักษร (เช่น ตัวอักษรบนไฟล์ PDF ที่มาจากการสแกน) ให้กลายเป็น ข้อความดิจิทัล ที่คอมพิวเตอร์สามารถอ่านและประมวลผลได้ โดยมันจะวิเคราะห์แพทเทิร์นของพิกเซลในรูปภาพเพื่อระบุว่าเป็นตัวอักษรใด แล้วจึงแปลงให้เป็นข้อความที่แก้ไขหรือค้นหาได้
หลังจากนั้นก็รับค่านั้นและทำการแปลงกับออกมาเป็นรูปด้วย library ต่างๆ เช่น opencv เป็นต้น
เหนือยิ่งกว่าปัจจุบัน การนำความรู้ไปประยุกต์ใช้และพัฒนาต่อ
หลักจากที่ได้อธิบายว่า AI นั้นมันน่าอัศจรรย์มากขนาดไหน เพราะหลังจากนี้เราไม่จำเป็นต้องหามรุ่งหามค่ำนั่งกรอกข้อมูลกันเป็นพันลวันแล้ว เรายังสามารถต่อยอดทำให้มัันอัตโนมัติได้ยิ่งขึ้นไปอีกด้วยนะAIM
หากเราเข้าไปที่ตรงหน้า chat ที่เราคุยกับ gemini ใน google ai studio
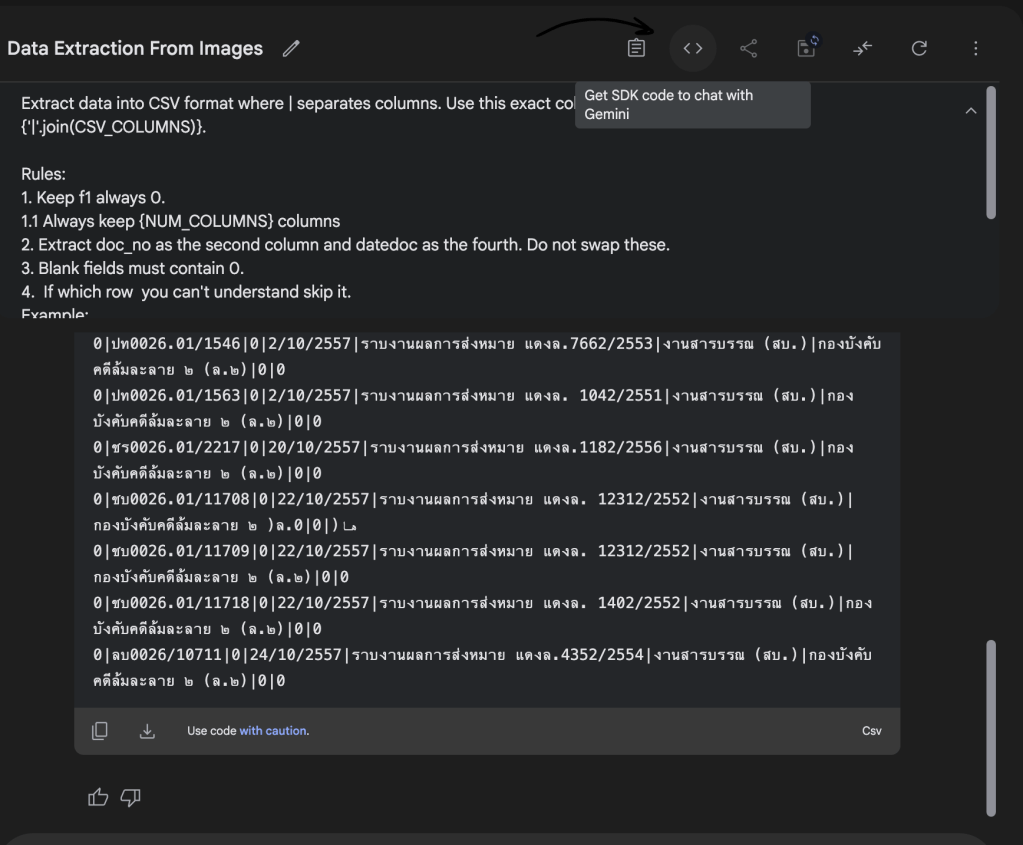
เราสามารถเปลี่ยน chat ที่เราคุยกับ gemini ให้เป็น code ที่ใช้รันผ่าน Terminal, หน้าเว็บไซต์ หรือจะเป็นยิงผ่าน Postman ก็ได้เหมือนกัน
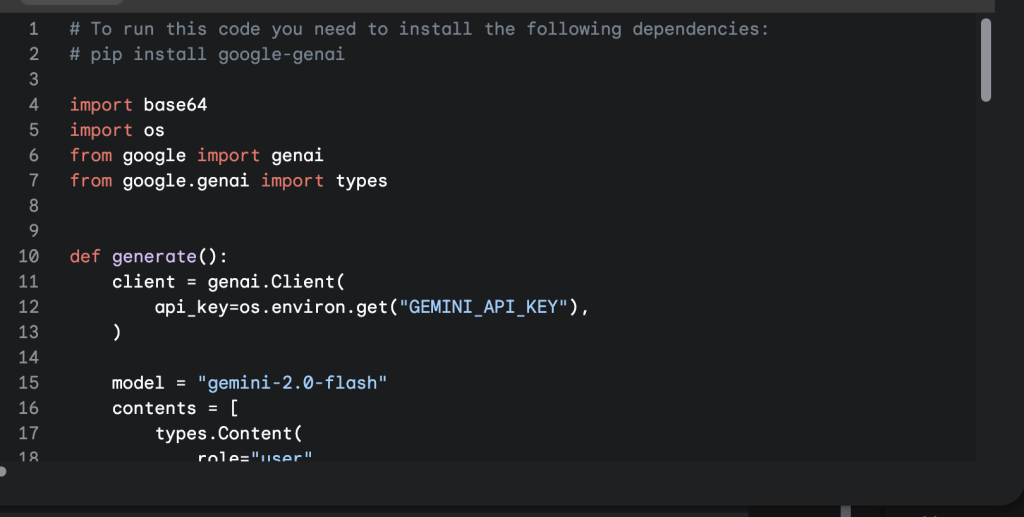
แต่ว่าการที่จะทำให้โค้ดนี้สมบูรณ์ได้นั้นเราต้องใช้ GEMINI_API_KEY ซึ่งถือเป็นอีกหนึ่งปัจจัยสำคัญเลย โดยการที่จะหามาได้นั้นเราก็แค่กดปุ่มด้านบนที่เขียนว่า Get API Key
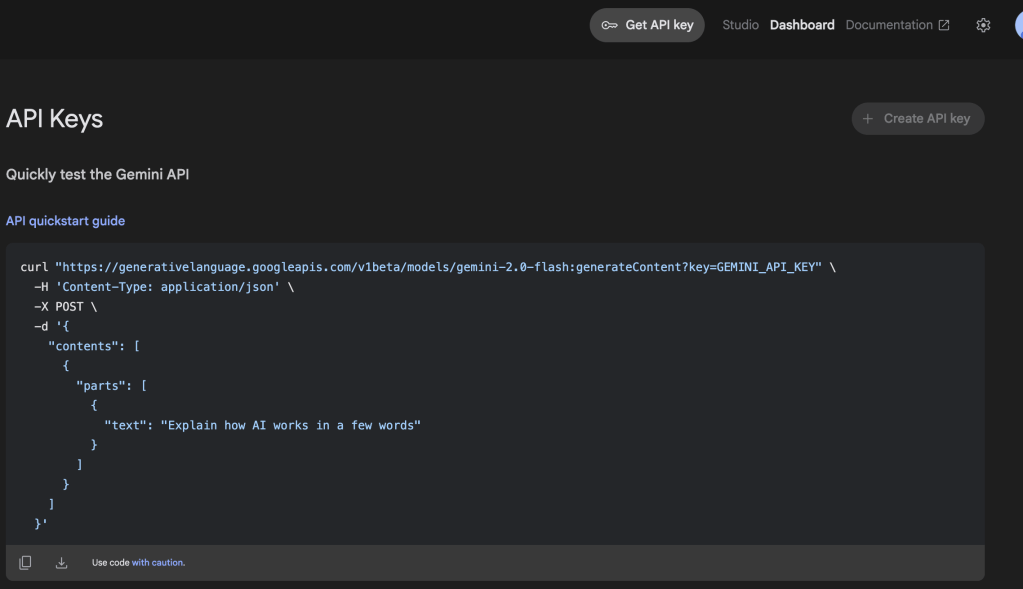
หลังจากนั้นให้ทำการกด + Create API Key google ai studio จะทำการค้นหา Google Cloud Project
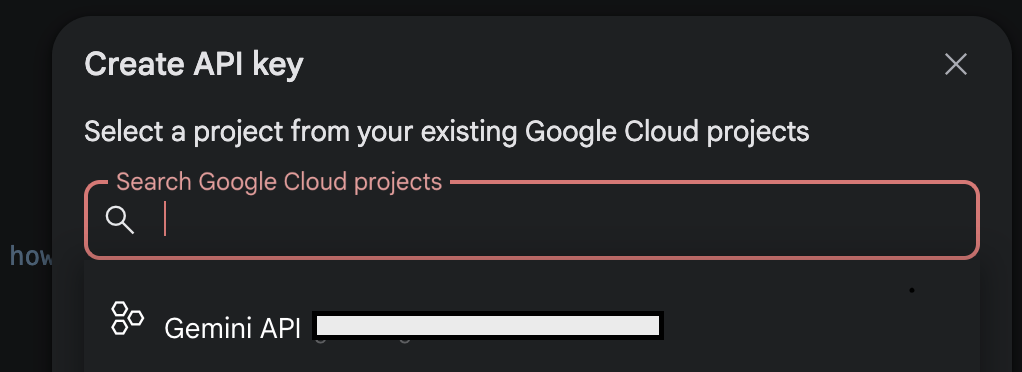
หากเพื่อนๆ พึ่งเคยสร้างโปรแกรมนี้ครั้งแรก เราแนะนำว่าให้เข้าไปสมัครและเปิดใช้งานในหน้า Google Cloud Project ก่อน https://cloud.google.com/?hl=en และเลือกไปที่ Console หากเราได้ทำการล้อคอิน Gmail เรียบร้อยแล้ว


เลือกเมนู New Project
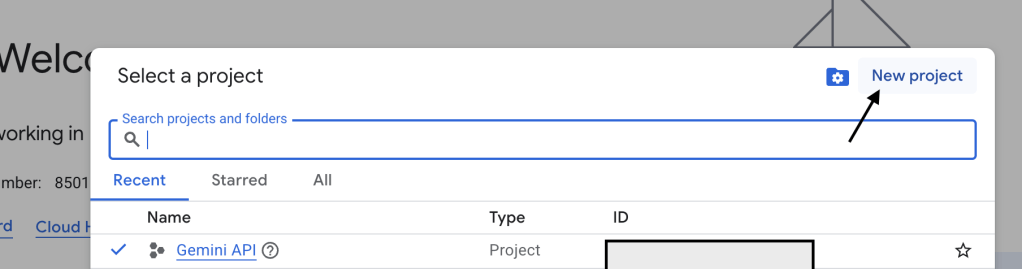
ทำการตั้งชื่อ Project name และเลือก Location (สามารถใช้ no organization เป็น default ได้)
รอจนหน้า Google Cloud Project แจ้งว่าเสร็จแล้วให้เราค้นหาในช่องค้นหาด้านบนว่า Gemini API และทำการ Enable ซะ
หลังจากที่ Enable แล้วให้กลับไปที่หน้า Google AI Studio และทำตามขั้นตอนการ Get API Key

ทีนี้เราก็จะเห็น Project ที่พึ่งสร้างแล้วกดคลิกเพื่อเลือกและกด Create API key in existing project
และเราก็จะได้ API Key เพื่อใช้เรียก service แล้ว แต่ระวังไว้ด้วยนะว่าอย่าเผลอแชร์ให้คนอื่นละไม่งั้นคุณจะโดนบิลอ่วมเลยละ
หลังจากนั้นก็กลับมาที่โค้ด copy และ วางในเครื่อง local เพื่อทดสอบเสียก่อน โดยเราสามารถเอา API_KEY ที่ได้วางแทนตรงนี้ได้เลยย
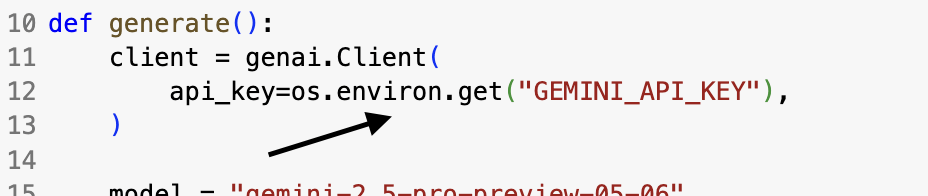
แต่การทำอย่างงั้นเรียกได้ว่าไม่ปลอดภัยเอาซะเลย เพราะฉะนั้นเราควรที่จะใช้ library อย่าง dotenv เพื่อมาอุดปัญหานี้โดย dotenv จะทำอ่านค่าบางอย่างจากไฟล์ที่ชื่อว่า .env ซึ่งเป็นไฟล์ที่เก็บตัวแปรต่างๆที่เราไม่อยากให้คนนอกรู้นั้นเอง
ทีนี้เราก็สามารถทดสอบโค้ดที่ google ai studio ให้มาได้แล้ว เย้
# To run this code you need to install the following dependencies:
# pip install google-genai
import base64
import os
from google import genai
from google.genai import types
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemini-2.5-pro-preview-05-06"
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""INSERT_INPUT_HERE"""),
],
),
]
generate_content_config = types.GenerateContentConfig(
response_mime_type="text/plain",
system_instruction=[
types.Part.from_text(text="""Extract data into CSV format where | separates columns. Use this exact column order:
{'|'.join(CSV_COLUMNS)}.
Rules:
1. Keep f1 always 0.
1.1 Always keep {NUM_COLUMNS} columns
2. Extract doc_no as the second column and datedoc as the fourth. Do not swap these.
3. Blank fields must contain 0.
4. If which row you can't understand skip it.
Example:
{'|'.join(CSV_COLUMNS)}
1|01038/2559|0|1/7/2559|รายงานการสำรองข้อมูลประจำเดือน มิย.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|เดินเรื่องเอง เดินเรื่องเอง|0
2|กบ0026/1222|0|30/6/2559|ขอส่งเงินค่าไฟฟ้าที่พักอาศัยเจ้าหน้าที่ ประจำเดือน พค.59|งานสารบรรณ (สบ.)|กองบริหารการคลัง (กค.)|0|0
Always make it {NUM_COLUMNS} columns
Ensure the output always aligns exactly to this structure."""),
],
)
for chunk in client.models.generate_content_stream(
model=model,
contents=contents,
config=generate_content_config,
):
print(chunk.text, end="")
if __name__ == "__main__":
generate()
อย่างไรก็ดีโค้ดที่ gemini ให้มานั้นยังทำงานได้แค่กับการ pass ค่า text เข้าไปได้เท่านั้นแถมยังเป็นการรันแบบ ถามตอบแค่ครั้งเดียว ซึ่ง โค้ดดังกล่าวนั้นยังไม่ตอบโจทย์ที่เราต้องนำมาแก้ไขเลย ผมก็เลยมีการแก้โค้ด โดยทำการเพิ่ม method ที่สามารถรับไฟล์เข้าไปเพื่อให้ Gemini Flash Model อ่านผ่าน OCR ได้นั้นเอง
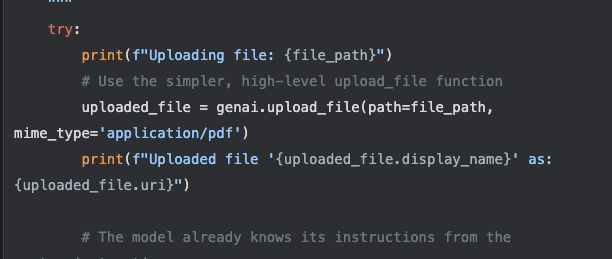
และเมื่อทำการอ่านค่าได้แล้วเราก็ต้องเพิ่มโค้ดอีกนิดนึงว่าแทนที่จะอ่านทีละไฟล์เราก็สร้าง loop ให้โค้ดของเราอ่านผ่านโฟลเดอร์ที่เก็บไฟล์เอาไว้จนกว่าจะหมดแปลงค่าออกมาเป็น csv format ให้เรานั้นเอง
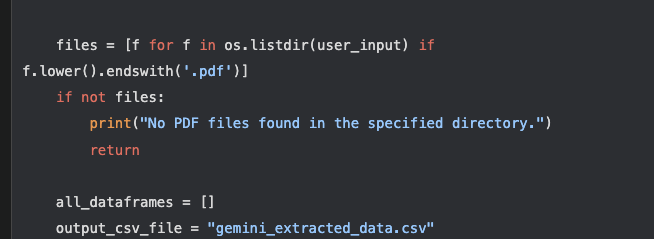
เมื่อ ถอดค่าจากไฟล์สแกนได้แล้ว เราก็บันทึกลง .csv ที่เตรียมไว้เพื่อที่เราจะเอาข้อมูลดังกล่าวไปใช้ในขั้นตอน INSERT ข้อมูลลงฐานข้อมูลได้ต่อไปนั้นเอง
Sourcecode
ผลที่ได้ลัพธ์
จากการที่เรานำ AI มาประยุกต์ใช้ทำให้ผมไม่ต้องมานั่งกรอกข้อมูลทีละบรรทัดและสามารถอัพข้อมูลเสร็จได้ทั้งสิ้น 265062 ไฟล์ โดยใช้เวลาเพียงแค่ 5 วัน ในการรันโค้ดทั้งหมด แทนที่จะใช้เวลาหลายเดือนนั้นเอง
ผมได้ทดลองให้คุณดูแล้วว่า AI นั้นมีประโยชน์มากแค่ไหนหากเราเข้าใจและใช้มันได้อย่างมีประสิทธิภาพ ผมว่ามันถึงตาคุณแล้วละที่จะต้องลองนำไปประยุกต์ใช้ เพื่อให้งานราชการของเรามีประสิทธิภาพมากขึ้นครับ คุณอาจจะลองเริ่มจากลองใช้ Google AI Studio ก่อนก็ได้ครับมันฟรี ลดกำแพงการศึกษาไปอี๊ก อยากให้คุณได้ลองสัมผัสนะครับ ละจะติดใจแน่นอน
References
For Gemini API – https://ai.google.dev/gemini-api/docs
For Encoder/Decoder – https://www.youtube.com/watch?v=Q7mS1VHm3Yw&t=7834s
