หากใครก็ตามที่คิดว่าจะเริ่มวิเคราะห์ข้อมูล ทำกราฟ หรืออะไรก็ตามแต่ ในยุคที่เทคโนโลยีนั้นเปลี่ยนผ่านไปอย่างรวดเร็ว ใครๆ ก็ล้วนนึกถึง Python หนึ่งในภาษาที่มีความยืดหยุ่นอย่างมาก สามารถวิเคราะห์ข้อมูล ทำนายผล และยังสามารถแสดงกราฟออกมาได้ แต่ในสมัยที่ยังไม่มี Python เราใช้อะไรในการทำกันล่ะ?
ภาษา R ถูกสร้างขึ้นในปี 1933 โดยมีจุดประสงค์เพื่อใช้งานในการคำนวณเชิงสถิติและการทำกราฟแบบต่างๆ โดยในปัจจุบันได้มีการพัฒนาส่วนเสริม (packages) ขึ้นมาเป็นจำนวนมากเพื่อให้รองรับการใช้งานสำหรับชาว Data Scientist

บทความนี้เป็นการนำสิ่งที่ผมได้เรียนรู้จากการอ่านหนังสือ ที่ชื่อว่า Hands-On Programming Project 1 และ 2 มาแชร์ให้เพื่อนๆฟังกันครับ การบ้านจากคอร์ส Data Science Bootcamp ของ DataRockie
Table of Contents
1. Weighted Dice
ภายในหนังสือนั้น จะนำเสนอตัวอย่างโค้ดและ syntax ผ่านการทดลองทำโปรเจกต์ง่ายๆ อย่างการทำลูกเต๋าสองลูกที่ถูกถ่วงน้ำหนัก ภายในหัวข้อนี้จะครอบคลุมเนื้อหาในส่วนที่เป็นพื้นฐาน ซึ่งหากคุณค่อยๆ ทำตามจะสามารถเข้าใจหลักการเขียนคำสั่งต่างๆ ดังนี้
- การเขียนคำสั่ง R
- การสร้าง R Object
- การเขียนฟังก์ชัน
- การโหลดใช้งานส่วนเสริม packages
- การสุ่ม
- การพล็อตกราฟอย่างง่าย
สมัยที่ผมยังเป็นเด็ก ผมเคยเชื่อว่าการรู้เรื่องสถิติและความน่าจะเป็นจะทำให้ผมได้อยู่บนกองเงินกองทอง ณ ดินแดนที่เต็มไปด้วยการพนัน อย่างลาสเวกัส แต่คุณเชื่อไหมว่าผมคิดผิด…
Garrett Grolemund
ในส่วนแรกของหนังสือ เราต้องโหลด RStudio Desktop และ R language ก่อนเพื่อเริ่มทำโปรเจคนี้
ภาษา R เป็น ภาษาประเภท dynamic-programming ภาษาที่คุณไม่จำเป็นจำต้อง compile เพื่อเปลี่ยนมันเป็นสิ่งที่คอมพิวเตอร์เข้าใจ เช่น ภาษา C หรือ JAVA
Basic Calculation Command
R สามารถทำ + - * / ได้เหมือนกับภาษาทั่วๆไป
10 + 2
## 12
12 * 3
36 - 3
## 33
33 / 3
## 11
Object
หากเราต้องการสร้าง ลูกเต๋า เราสามารถใช้ : เพื่อสร้าง vector data type ที่เก็บค่าแค่มิติเดียว
1:6
## 1 2 3 4 5 6
แต่ว่าการที่เราไม่ได้ assign ค่าให้เข้ากับ ตัวแปรบางอย่างจะทำให้เราไม่สามารถใช้งานมันได้ เนื่องจากไม่ได้บันทึกค่า ลงใน computer’s memory โดยเราสามารถบันทึกค่า ลงตัวแปร object ได้ดังนี้
a <- 1
die <- 1:6 # ทำการบันทึก vector 1:6 ลงในตัวแปร die
เครื่องหมาย < - จะบอกให้คอมพิวเตอร์ทำการ assign ค่า ลงไปในตัวแปรทางซ้ายมือของเรา
R เป็น ภาษา case-sensitive เพราะฉะนั้น Name กับ name ถือว่าเป็นคนละตัวแปร
R ห้ามตั้งชื่อโดยขึ้นต้นด้วยตัวเลข และ ห้ามใช้ special case ด้วย
เราสามารถใช้คำสั่ง ls() เพื่อดูว่าเราได้ประกาศตัวแปรอะไรไปแล้วบ้าง

ในภาษา R นั้น จะไม่ได้ยึดหลักการ คูณ Matrix เหมือนใน Linear Algebra แต่จะใช้วิธีการที่เรียกว่า element-wise execution ซึ่งเป็นการทำ operation โดยจับคู่ vector สองอันมาเทียบกัน
หาก vector สองอันที่เอามาใช้ ยาว ไม่เท่ากัน R จะทำการวนลูปจน ตัวที่สั้นไปบนตัวที่ยาวจนครบ แล้วค่อยทำ operation เราเรียกว่า vector recycling

เราสามารถใช้ %*% สำหรับการคูณแบบเมทริกซ์ และ %o% สำหรับการคูณแบบ outer product
Function
ภายใน R มี built-in ฟังก์ชัน ให้ใช้งานอยู่หลายแบบ ไม่ว่าจะเป็น round, factorial, mean
R จะรัน ฟังก์ชัน จากในสุดออกไปด้านนอก ดังตัวอย่าง

สำหรับใน การ สุ่มเต๋านั้น เราจะใช้ sample ฟังก์ชัน ที่รับ argument 2 ค่า โดย รับเป็น vector กับ จำนวนผลลัพธ์ที่จะ return ออกมา
sample(x = die, size = 1)
## 2
ในหลายๆครั้ง เรา ไม่รู้หรอกว่า ฟังก์ชัน ดังกล่าวรับ argument ชื่ออะไรบ้าง เพราะฉะนั้นเราสามารถใช้คำสั่ง args() เพื่อเช็คได้

หากเราสังเกตจะพบว่า หากเราไม่เรียกใช้ parameter replace ลูกเต๋าของเราก็จะไม่สุ่มหน้าซ้ำ ซึ่งมันก็จะผิดหลักการการสุ่มลูกเต๋า
อย่างไรก็ตาม การที่เราต้องมานั่ง run commands อย่าง sample และ sum ทุกครั้งมันก็คงจะเป็นการทำที่น่าเบื่อหน่าย เพราะฉะนั้นเราจึงจะสร้าง ฟังก์ชัน ของเรามาใช้เอง
my_function ← function() {}
roll <-function() {
die <- 1:6
dice <- sample(die, size = 2, replace = TRUE)
sum(dice)
}
โค้ดที่เรานำไปวางไว้ภายในวงเล็บปีกกาเรียกว่า body ของ ฟังก์ชัน นั้นๆ เพราะฉะนั้น บรรทัดสุดท้ายของโค้ด จะต้องคืนค่าบางอย่างกลับมา อย่างไรก็ตาม จากตัวอย่างข้างต้น การที่เราจะต้องมาประกาศตัวแปร die ทุกครั้งที่เรียกฟังก์ชั่น ก็กระไรอยู่ ทำไมเราไม่นำมาไว้ข้างนอก แล้วเอาส่งเข้าไปล่ะ
bones <- 1:6
roll <-function(bones) {
dice <- sample(x= bones, size = 2, replace = TRUE)
}
roll(bones)
อย่างไรก็ตาม ในกรณีนี้หากเรา ไม่ได้ระบุค่า bones จะทำให้ ฟังก์ชัน ของเรา error เพราะฉะนั้นเราควรกำหนดค่า default ให้ funciton
roll2 <-function(bones = 1:6) {
dice <- sample(bones, size = 2, replace = TRUE)
sum(dice)
}
ใน R คุณสามารถสร้าง ฟังก์ชัน ด้วยตัวเองมากแค่ไหนก็ได้ แตกต่างจาก tools สำเร็จรูปอย่าง excel คุณเคยสร้างเมนูใหม่ใน Excel หรือไม่ เพราะฉะนั้นการที่คุณสามารถเขียน programming ได้เอง จะช่วยให้คุณเปิดกว้างได้มากขึ้น
R สามารถเก็บค่าประเภท binary และ ค่า complex number ได้เช่นกัน
2. Playing Card
ภายในโปรเจคที่สอง นี้เราจะมาสร้างการ์ดเกมโดยคุณจะได้เรียนรู้การ เก็บ เรียกใช้ และการเปลี่ยนแปลค่าของข้อมูลใน computer’s memory
สกิลเหล่านี้จะช่วยให้คุณ จัดการกับข้อมูลโดยปราศจาก error เราจะออกแบบเด็ดสำหรับการเล่นที่เราสามารถแจกหรือสลับก็ได้ โดยเด็ดนี้จะจำว่าการ์ดใบไหนได้แจกไปแล้วบ้าง
- ในโปรเจคนี้เราจะได้เรียนการบันทึกประเภทข้อมูล เช่น string และ boolean
- บันทึกข้อมลในรูปแบบ vector matrix array list และ dataframe
- โหลดและบันทึกข้อมูลด้วย R
- รับข้อมูลจาก data set
- เปลี่ยนค่าข้อมูลใน data set
- เขียน เทสสำหรับ logics
- การใช้ NA
Task 1: build the deck
atomic vector – simple vector ที่เราได้เรียนไปในบทที่ 1 อย่าง die โดยเราสามารถใช้คำสั่ง is.vector เพื่อเช็คประเภทข้อมูลได้ โดยการบันทึกค่าเพียงค่าเดียวก็นับเป็น atomic vector เช่นกัน
เราสามารถเขียน 1L ภายใน atomic vector เพื่อระบุค่าว่าเป็น number vecotr ได้
length เป็น ฟังก์ชั่นที่ใช้ในการนับความยาวของ atomic vector
เราสามารถใช้ typeof เพื่อระบุประเภทของข้อมูลว่าเป็นข้อมูลประเภทอะไรใน R
คำว่า doubles และ numerics นั้นมีความหมายเหมือนกัน แต่ว่าคำว่า double เป็นคำที่นิยมใช้ในแวดวง programming เพื่อสื่อถึงจำนวน bytes ที่คอมพิวเตอร์ใช้ในการเก็บค่าข้อมูล
โดยปกติแล้วหากเราไม่ระบุ L. ท้ายตัวเลขนั้น R จะบันทึกค่าเป็น double โดยค่ายังเหมือนกัน แตกต่างที่ type เท่านั้น อย่างไรก็ตามเราไม่สามารถบันทึกทุกค่าเป็น doubles ได้เพราะว่าคอมพิวเตอร์จะใช้ 64bits สำหรับการเก็บ ค่าdoubles เพราะฉะนั้น ค่า doublesใน R จะมีทศนิยมแค่ 16.ตำแหน่งเท่านั้น
ซึ่งเหตุการณ์เหล่านี้ เรียกว่า floating-point error ซึ่งคุณสามารถพบได้เมื่อทำการคำนวณค่าด้วย ตัวเลขที่มีทศนิยม เราเรียกปัญหานี้ว่า floating-point arithmetics
เราสามารถเขียน TRUE FALSE ใน R ด้วย T F ได้เช่นกัน
เราสามารถใช้คำสั่ง attributes เพื่อเช็คว่า object ดังกล่าวมี attributes อะไรบ้าง โดย NULL คือค่าที่จะแสดงออกมในกรณีที่เป็น null set หรือ empty object
ฟังก์ชัน names() เป็น ฟังก์ชั่นที่ใช้ในการตั้งชื่อ ให้กับ atomic vector, dim, classes
อย่างเช่นเราสามารถตั้งชื่อให้ค่าในลูกเต๋าเราได้
names(die) <- c("one", "two", "three", "four", "five", "six")
## one two three four five six
## 1 2 3 4 5 6
แต่ว่าหากเรา +1 ค่าใน die ชื่อก็จะไม่ได้เปลี่ยนตามอยู่ดี โดยหากต้องการนำออกให้ assign เป็น NULL
เราสามารถเปลี่ยน ค่า atomic vector ไปเป็น dimensional array โดย assign ค่า number vector ไปที่ attribute dim
โดย ค่าที่อยู๋ dimensional array นั้นจะเริ่มจากค่า rows ก่อนเสมอ
เราสามารถสร้าง matrix ด้วยการเรียกใช้ ฟังก์ชัน ที่ชื่อว่า matrix โดยการป้อน argument number vector, จำนวนแถว และค่า boolean สำหรับการบอกว่าให้เติมแบบแถวต่อแถวหรือไม่
m <- matrix(die, nrow = 2, byrow = TRUE)
## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
การที่เราเปลี่ยนแปลง dimension ของ object นั้นจะไม่ได้เปลีย่น type แต่จะเปลี่ยน class ของ object นั้นแทน
dim(die) <- c(2, 3)
typeof(die)
## "double"
class(die)
## "matrix"
เราสามารถเรียกใช้ Sys.time() เพื่อรับค่าเวลาได้ แต่ว่า type ของมันจะเป็น double และ class จะเป็น POSIXct POSIXt
POSIXct เป็น framework ที่คนนิยมใช้เพื่อการแสดงค่าวันที่และเวลา โดย เวลาใน POSIXct จะแสดงค่าด้วยจำนวนเวลาที่ได้ผ่านไปแล้วนับตั้งแต่วันที่ January 1st 1970
หากเราใช้คำสั่ง unclass เราก็จะพบกับค่าตัวเลขที่ อยู่เบื้องหลัง วันที่และเวลา ในทางกลับกัน เราก็สามารถ assign class ให้กับตัวเลขเพื่อให้ได้วันที่ได้เช่นกัน
now <- Sys.time()
unclass(now)
## 1395057600
mil <- 1000000
mil
## 1e+06
class(mil) <- c("POSIXct", "POSIXt")
mil
factors คือ ฟังก์ชัน ที่เราไว้ใช้เก็ฐค่าประเภท categorical information.
Coercion
เป็นหลักการที่ R จะทำการเปลียนค่าของ data types เช่น หากมีค่า character string ใน atomic vector R จะเปลี่ยนค่าทั้งหมดเป็น string
หากเป็นค่า logical และมี numerics อยู่ก็จะเปลี่ยนเป็น 0 หรือ 1 แทน
เราสามารถเรียกช้คำสั่ง as.character(gender) เพื่อให้ค่าปลี่ยนเป็น character string
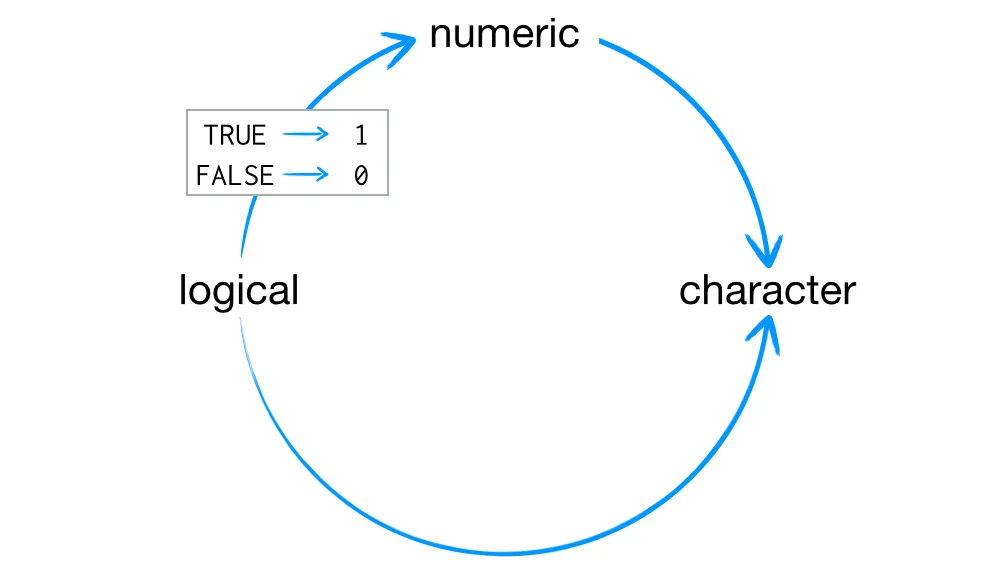
อย่างไรก็ตาม การเรียนรู้ data types ด้านบนนั้นไม่สามารถนำมาใช้ในการสร้าง card deck ได้เพราะพวกมันเก็บ data type ได้แค่แบบเดียว
list สามารถเก็บค่า ได้หลายรูปแบบ เช่น
card <- list("ace", "hearts", 1)
card
## [[1]]
## [1] "ace"
##
## [[2]]
## [1] "hearts"
##
## [[3]]
## [1] 1
list สามารถเก็บค่า การ์ดทั้งสำรับให้เราได้แต่เราก็คงจะไม่ทำเช่นกัน นั้นจึงเป็นที่มาของ Data Frames two-dimensional version of a list.
ค่า character string ด้านในที่บันทึกไว้จะเป็น factors ทั้งหมด หากคุณไม่อยากได้สามารถกำหนด parameter ที่ชื่อว่า stringsAsFactors ให้เป็น false
df <-data.frame(face =c("ace", "two", "six"),
suit =c("clubs", "clubs", "clubs"), value =c(1, 2, 3))
df
## face suit value
## ace clubs 1
## two clubs 2
## six clubs 3
ในการสร้าง data frames นั้นคุณจำเป็นต้องมั่นใจว่า ข้อมูลของคุณนั้นยาวเท่ากันในแต่ละ vector ไม่เช่นนั้นคุณต้องทำ recycling rules เพื่อให้มีคววามยาวเท่ากัน
สำหรับ data frame แล้ว มี type เป็น list แต่ว่าหากเราเช็ค class เราก็จะได้เป็น data.frame
ในแบบทดสอบนี้ในหนังสือได้เตรียมไฟล์ csv ไว้ให้แล้วเนื่องจากการที่เราต้องามาสร้าง deck เองเนี้ยโอกาสเกิด error ค่อนข้างเยอะจึงไม่ควรพิมพ์เยอะขนาดนั้น
โดยเราสามารถเรียกใช้คำสั่ง read.csv ในการอ่านไฟล์ได้
Task 2: 2 functions
ในการเล่นเกมการ์ดนั้น เราต้องสามารถสลับกองไพ่และจั่วใบบนสุดเพื่อแจกได้ เพราะฉะนั้นเราต้องเขียน ฟังก์ชัน สองอันเพื่อมาารองรับ การทำงานสองสิ่งนี้
- Positive integers
deck[1, c(1, 2, 3)]- ถ้าเราเขียนซ้ำด้วยการใส่ vector ลงไป R ก็จะแสดงค่าซ้ำด้วย
- Negative integers
deck[-2(2:52), 1:3]- จะดึงค่าที่เราไมได้กำหนดอออกมา เช่นกรณีก็จะดึงมาแค่ king spades 13
- ง่ายต่อการทำ subset
- เราสามารถใส่ จำนวนเต็มบวก และ ลบ ใน vector เดียวกันเพื่อดึงค่าออกมา
deck[c(-1, 1), 1]
- Zero – แม้ว่าจะไม่ใช่ทั้งจำนวนเต็มบวกและลบ แต่่คุณก็จะได้ data frame เปล่ามาอยู่ดี
deck[0, 0] ## data frame with 0 columns and 0 rows - Blank spaces – การเว้นว่างไว้ เป็นการบอก R ให้ว่า เอาค่าในทุกๆอันใน row หรือ column มา
- Logical values การใส่ atomic vector ของ logic ลงไป R จะพยายาม match ค่า แล้วดึงข้อมูลออกมาแค่เฉพาะค่าที่ ป็น True เท่านั้น
deck[ , "value"]
deck[1, **c**("face", "suit", "value")]
- Names – เราสามารถดึงข้อมูลด้วย ชื่อ ได้เช่นกัน
โดยปกติแล้วเราก็จะใช้ deck[ , ] ในการนำค่าออกมา โดย หลักแรกจะแทน row และหลักสองจะแทน column เราสามารถสร้าง index ได้หลายรูปแบบดังนี้
ใน R นั้น index จะเริ่มที่ 1 ไม่ใช่ 0
ในกรณีท่ี่เรา เลือกค่ามาแค่ 1 column เราจะได้แค่ เป็น vector หากอยากได้ data frames เราต้องกำหนด drop = False
ทีนี้เราจะมาสร้าง ฟังก์ชัน สลับการ์ดกัน
deal <- ฟังก์ชัน(cards) {
cards[1, ]
}
เบื้องต้นหากเราใส่ 1 ลงไป เราก็จะได้การ์ดใบบนสุดของ deck มาแต่ ว่าในการเล่นจริงนั้น เราต้องการให้กองไพ่นั้น สลับและไม่อยู่ใน ลำดับเดิมตลอดเวลา เพราะฉะนั้นแทนที่เราจะใส่ 1:52 เราก็จะใส่เป็น random order เข้าไปแทน
shuffle <- ฟังก์ชัน(cards) {
random <- sample(x= 1:52, size = 52)
cards[random,]
}
ทีนี้เราก็สามารถสลับการ์ดหลังจาก เราแจกไพ่ได้แล้ว
deal(deck)
## face suit value
## king spades 13
deck2 <-shuffle(deck)
deal(deck2)
## face suit value
## jack clubs 11
เราสามารถดึงค่ามาเป็น vector ได้ด้วย $ เช่น deck$value สิ่งนี้จะมีประโยชน์มากเพราะว่าเราสามารถใช้ค่า numeric vector ในการ ทำงานด้าน math ได้ เช่น mean หรือ median
เราสามารถใช้ [[]] ในการ subset ค่าได้เช่นกันในกรณีที่เราไม่มีชื่อ ให้กับ list นั้น
lst[[1]]
## 1 2
หากเรา ใช้แค่ [] เราจะได้ list ของ column แต่หากใช้ [[ ]] เราจะได้ค่าของ vector นั้นแทน
Task 3: change the point system to suit your game
เราสามารถ assign ค่าเข้าไปใน atomic. vector ได้
vec[1] <- 1000
vec
## 1000 0 0 0 0 0
ด้วยวิธีนี้เราก็สามารถสร้าง column ใหม่ได้
deck2$new <- 1:52
deck2$new <- NULL
โดยปกติแล้วการ ดึงข้อมูลและแก้ข้อมูลเป็นเรื่องง่ายหากเรารู้ตำแหน่ง แต่หากเราไม่รู้ เราก็จำเป็นที่จะต้องนำ การทำ subset ด้วย logic เข้ามาช่วย
deck3$value[deck3$face == "ace"] <- 14
| Operator | Syntax | Tests |
|---|---|---|
& | cond1 & cond2 | Are both cond1 and cond2 true? |
| ` | ` | `cond1 |
xor | xor(cond1, cond2) | Is exactly one of cond1 and cond2 true? |
! | !cond1 | Is cond1 false? (e.g., ! flips the results of a logical test) |
any | any(cond1, cond2, cond3, ...) | Are any of the conditions true? |
all | all(cond1, cond2, cond3, ...) | Are all of the conditions true? |
| Operator | Syntax | Tests |
|---|---|---|
> | a > b | Is a greater than b? |
>= | a >= b | Is a greater than or equal to b? |
< | a < b | Is a less than b? |
<= | a <= b | Is a less than or equal to b? |
== | a == b | Is a equal to b? |
!= | a != b | Is a not equal to b? |
%in% | a %in% c(a, b, c) | Is a in the group c(a, b, c)? |
บ่อยครั้งที่ค่าบางค่านั้นหายไป ใน R เราจะใช้ NA ในการบอกว่า not available NA ช่วยให้ ข้อมูลของเราสามารถนำมาทำด้านสถิติได้แต่บางครั้งเวลาหาค่าทางคณิตศาสตร์ อาจจะทำให้ค่า error ได้ เพราะฉะนั้น บาง ฟังก์ชัน จะมี parameter อย่าง na.rm ที่ให้เรา set True เพื่อไม่นำมาคำนวณ
เราสามารถใช้ is.na() ในการหาว่าใน data type นั้นมีค่า NA หรือไม่
Task 4: manage the state of the deckฃ
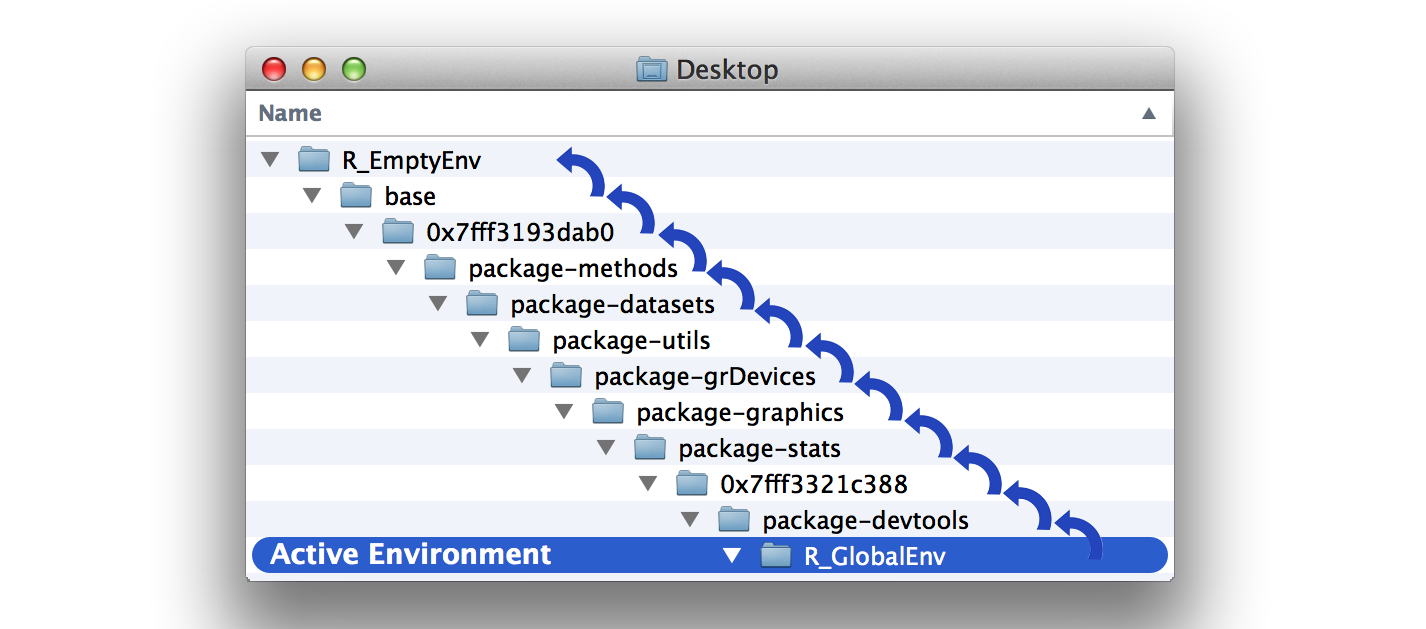
R เก็บข้อมูลใน environment คล้ายกับเวลาเราเก็บไฟล์ใน โฟลเดอร์ต่าง เราสามารถใช้ parevns ฟังก์ชั่น ใน package pryr
ใน environment tree เราสามารถเข้าถึงค่า globalenv() baseenv() emptyenv() ได้
เราสามารถใช้ ls หรือ ls.str ในการดู objects ที่บันทึกใน environments โดย ls จะให้ดูแค่ชื่อ แต่ ls.str จะดู structure.ได้ด้วย
โดยค่าทั้งหมดที่ เราได้ บันทึกนั้นจะอยู่ใน global environment และเรายังสามารถใช้ assign() เพื่อ เพิ่มค่า ลงไปใน global environment ได้เช่นกัน
โดยทั่วไปแล้ว global environment จะเป็น active environment แต่หากเรา รัน ฟังก์ชัน บางอย่างอาจทำให้ค่า active environment เปลี่ยนไปได้
ใน R. เวลา R หาค่านั้นจะมีกฎอยู่ 3 ข้อ
- R จะหาค่าใน active environment ก่อน
- ถ้าทำงานใน CLI global environment จะเป็น active environment
- หาก R หาไม่เจอใน environemnt R จะมองหา object นั้น parent environment
เวลาที่เรา run ฟังก์ชัน R จะสร้าง environment ขึ้นมาใหม่ที่ runtime เกิดขึ้น หลังจากนั้นจะเอา result ส่งกลับไป environment ที่เราบันทึก ฟังก์ชัน ไว้
อย่างเช่นใน กรณีตัวอย่างนี้ เราจะพบว่า ตอนรันข้อมูลด้านใน ฟังก์ชั่น show_env active environment จะเป็นอันที่อยู่ภายใต้ GlobalEnv หรือก็คือ parent environment
show_env <- ฟังก์ชัน(){
list(ran.in = environment(),
parent = parent.env(environment()),
objects = ls.str(environment()))
}
show_env()
global environment ไม่จำเป็นต้องเป็น parent ยกตัวอย่างเช่น หากเราเรียก ฟังก์ชัน parenvs() parent env ก็จะมาจาก pryr ซึ่งก็คือที่ๆ ตัวฟังก์ชั่นนี้ถูกสร้างครั้งแรกนั้นเอง
และด้วยเหตุนี้ มันก็จะมี ฟังก์ชัน block เพราะว่า R ก็จะบันทึก object ไว้ใน runtime environment เพื่อให้มั่นใจว่าไม่มีค่าไหนใน global ถูกเขียนทับ
ในกรณีที่มีการส่ง arguments R ก็จะ copy ค่าเข้าไปใน runtime environment ด้วยเช่นกัน
สรุปก็คือ สมมติว่าเรากำลังรันโค้ดใน ภาษา R อยู่ตอนแรก โค้ดเราก็จะรันใน active environment ซึ่งเป็น environment ที่ใช้ call ฟังก์ชัน เมื่อเรียก ฟังก์ชัน R จะทำการ ตั้ง runtime environment แล้ว copy ค่าใน argument เข้ามาใน environment นี้ด้วย หลังจากนั้นก็จะรันโค้ดใน ฟังก์ชัน body หากมีการ assign ค่าก็ เก็บไว้ใน runtime environment หากมีการเรียกใช้ object ที่ไม่มีใน runtime environment ก็จะทำตาม scoping rule แล้วไล่หาใน parent environment หลังจากที่รัน ฟังก์ชัน เสร็จแล้ว R ก็จะเปลี่ยนกลับมาใช้ environment ที่เรียก ฟังก์ชัน หากมีการ assign ค่าที่ return จากฟังก์ชั่นเราก็จะ เอาค่านั้นมาบันทึกที่ environment
เราสามารถใช้ความรู้นี้มาปรับใช้กับเกมการ์ดของเราได้ เพราะ เมื่อเราทำการแจกไพ่นั้นไปแล้วเราก็ไม่ควรแจกไพ่เดิมให้คนใหม่ได้ เราก็จะใช้ assign มาแก้ตรงจุดนี้ ทีนี้เราก็สามารถสลับการ์ดและแจกการ์ดโดยที่ แจกไพ่นั้นไปได้แล้ว
หากเราต้องการจะทำให้มั่นใจว่า สำรับที่เราเล่นจะไม่ถูกทำให้หายระหว่างที่เล่น เราก็สามารถสร้าง ฟังก์ชัน setup ขึ้นมาเพื่อสร้างอีก environment นึงในเก็บค่าได้เช่นกัน
setup <-ฟังก์ชัน(deck) {
DECK <- deck
DEAL <-ฟังก์ชัน() {
card <- deck[1, ]
assign("deck", deck[-1, ], envir =parent.env(environment()))
card
}
SHUFFLE <-ฟังก์ชัน(){
random <-sample(1:52, size = 52)
assign("deck", DECK[random, ], envir =parent.env(environment()))
}
list(deal = DEAL, shuffle = SHUFFLE)
}
cards <-setup(deck)
deal <- cards$deal
shuffle <- cards$shuffle
ทีนี้หากเราเผลอลบ deck ในชั้น globalไปเราก็ยังเล่นได้อยู่ดี
และนั่นคือทั้งหมดของ Hands-ON Programming with R ใน chapter 1 และ 2 ในบทความถัดไปเราจะมาพูดถึง สิ่งที่ผมได้เรียนรู้เพิ่มเติมกันครับ

{kind=link}
{kind=link}