ตั้งแต่ช่วงต้นปีที่ผ่านมา ผมเชื่อว่าทุกคนต้องเคยเลื่อนผ่าน ไม่ว่าจะเป็น Youtube Short, Facebook Reel , Instragram หรือ เจ้าแม่ short video อย่าง Tiktok ผมเชื่อว่าทุกคนต้องเคยเห็นคลิปวีดิโอที่ทำมาจาก AI ต่างๆนานา อย่างแน่นอนใช่ไหมครับ
ด้วยความสงสัย และ ใคร่รู้ว่า เอ้ย คนพวกนี้เขาทำกันยังไงนะ ละแบบเขามาโพสต่อเนื่องกันได้ทุกวี่ทุกวันเลยหรอ ละแบบ แต่ละคลิปก็ดูไม่ค่อยซ้ำกันเลยคิดได้ไงนะ
ด้วยเหตุนี้ผมจึงตัดสินใจที่ลองหาข้อมูล ละก็ไปเจอว่า เออ มันมี Tools ตัวหนึ่งที่เอาไว้ทำ Workflow Automation ชื่อ n8n (เอน-เอ็ท-เอน) นั้นเอง
ผมจึงหยิบเจ้าซอฟแวร์ตัวเนี้ย ไหนมาลองเล่นบ้างสิ ไปๆมาๆ ก็รู้สึกว่า มันเป็น Low Code ที่สะดวกมากกกกก และสามารถเชื่อมต่อกับโลกอินเตอร์เน็ตได้อย่างไร้ขีดจำกัดเลยทีเดียว
และมันก็ทำให้ผมสามารถนำไปประยุกต์ใช้กับงานราชการได้อย่างดีเยี่ยมเลยละครับ ระบบงานที่ขึ้นชื่อเรื่องความเยอะ และ ต้องลีนยิ่งกว่า Startup เสียอีก 555+
เนื้อหาในบทความนี้ผมจะมาเล่า และ อธิบายว่า n8n คืออะไรแล้วมันดียังไงกันครับ และแถมด้วยการพาดู Workflow แบบ basic ที่ใครๆก็สามารถนำไปลองทำได้
Table of Content
- ทำความรู้จัก N8N
- ทำไม n8n ถึงเหมาะกับงานราชการ
- n8n ให้บริการรูปแบบไหนบ้าง ( Cloud & Self-hosted )
- ข้อควรระวังในการใช้งานข้อมูล
- มาลองติดตั้ง n8n กันเถ๊อะ
- ทดลองทำ Workflow ง่ายๆ 1 อัน
- บทสรุป
1. ทำความรู้จัก n8n
n8n (เอ็น-เอท-เอ็น) เป็นระบบให้บริการทางด้านซอฟแวร์สำหรับการทำกระบวนการอัตโนมัติ (Workflow Automation) ที่ผสมผสานความสามารถของ AI กับกระบวนการทางด้านธุรกิจได้อย่างลงตัว
ด้วยความที่ซอฟแวร์ไม่ต้องพึ่งพาทักษะในด้านการเขียนโปรแกรมมากนัก ทำให้รอยต่อระหว่างฝั่งธุรกิจ (business) และ ฝั่งนักพัฒนา (developer) นั้นแคบลง และช่วยให้เกิดความหยืดยุ่นเป็นอย่างมากกับบริษัท
บน n8n นั้น มีสิ่งที่เรียกว่า Nodes เพื่อใช้ในการเชื่อมโยงแพลทฟอร์มอื่นๆมากกว่า 500 รายการซึ่งจะช่วยให้คุณสามารถเข้าถึงและเชื่อมโยงสิ่งๆต่างรอบตัวคุณได้อย่างมีประสิทธิภาพสุดๆ
2. ทำไม n8n ถึงเหมาะกับงานราชการ
หลายท่านที่ทำงานในราชการมันทั้งจำเจ วกวน และวุ่นวายแค่ไหน ?
ทั้งงานเอกสาร การประชุม การส่งไปอบรม และอื่นๆอีกร้อยแปดพันเก้าที่แสนจะวุ่นวาย
ไหนจะจำนวนคนที่น้อย อย่างผมทำงานด้านคอมพิวเตอร์ มีคนอยู่หยิบมือ แต่งานกองเท่าภูเขาเลากา ทำไปก็บ่นไป ด้วยเหตุนี้ถ้าเราสามารถลดงานเรานี้ได้และผลักภาระงานสุดแสนจะน่าเบื่อนี้ให้ ใครเป็นคนทำมันจะดีกว่าไหมละ ?
ลองจินตนาการตามผมนะครับ คุณมีเวลาให้ตัวเองมากขึ้น สามารถพัฒนาคุณภาพชีวิตตัวเองเอ่ย คุณภาพทีมของคุณเอ่ย หรือไปจนถึงพัฒนาการทำงานในระดับองค์กรดูสิ
หรือไม่ต้องพัฒนาลงพัฒนาอะไรหรอก เอาแค่มีเวลาได้นอนตีพุงอยู่บ้าน ดู Netflix ชิวๆ และเลิกงานตรงเวลา แค่นี้ชีวิตก็โคตรจะสบายแล้วครับผมว่า
ผมลองมาคิดคร่าวๆ ซัก 5-10 ไอเดีย ที่จะช่วยลดงานข้าราชการทั้งด้านเอกสาร ด้านภาคบริการประชาชน และด้านพัฒนาตนเอง เช่น
- Workflow ที่จะช่วยงานของทีม HR ในการเพิ่มผู้ใช้งานระบบได้เร็วขึ้น (Onboarding Workflow Automation)
- Workflow สำหรับแจ้งเตือนเมื่อระบบมีปัญหา (Alerting Workflow)
- Workflow สำหรับแจ้งซ่อมผ่านทางระบบแชทไลน์ (Support Service Automation Workflow)
- Chatbot สำหรับถามตอบให้ลูกค้าไปยังระบบได้ถูกต้อง (Intelligence Chatbot) ที่กรมบังคับคดี เรามีระบบเยอะมาก เยอะจนงง เยอะจนคนในยังลืมว่าระบบอะไร Silo ไปอี๊กกก
- Workflow สำหรับทำเรื่องเปลียนรหัสผ่านสำหรับผู้ใช้งานภายใน (Forget Password Automation Workflow).
เห็นไหมครับ ? ถ้าเราเอามาลดงานพวกนี้น้า เราจะมีเวลาไปทำอย่างอื่น หรือพักผ่อนได้อีกเยอะเลย แถมอาจจะช่วยให้เรารู้สึกเครียดน้อยลงได้อีกด้วย
เอาละหลังจากเราสาธยายความดีงามของมันมามากพอละ ปะ ไปดูว่า n8n มีแบบไหนบ้าง
3. n8n ให้บริการรูปแบบไหนบ้าง ( Cloud & Self-hosted )
n8n มีรูปแบบการให้บริการหลัก ๆ สองแบบได้แก่ Self-hosted และ Cloud Subscription เรามาเริ่มกันที่ Cloud Subscription กันก่อน

Cloud Subscription
สำหรับเวอร์ชั่นนี้เป็น iPaaS (Integration Platform as a Service) เหมือนกับพวก Make หรือ Zapier เลย ก็คือเราเสียเงินค่า Subscription เราก็สามารถเข้าไปใช้งานได้ทันทีเลย เรียกได้ว่าใช้เงินแก้ปัญหา
ข้อดีเด่น ๆ ของ Cloud Subscription คือ:
เริ่มงานได้ไว: ช่วยให้คุณสามารถโฟกัสกับการสร้าง Workflow ได้ทันที โดยไม่ต้องเสียเวลาไปกับการตั้งค่าระบบพื้นฐาน
ความสะดวกสบาย: คุณไม่ต้องกังวลเรื่องการติดตั้งเซิร์ฟเวอร์, การดูแลความปลอดภัย, การจัดการ SSL Certificate ประจำปี หรือการอัปเดตเวอร์ชันซอฟต์แวร์ เพราะ n8n เป็นผู้ดูแลจัดการให้ทั้งหมด
ทีนี้เราลองมาดูด้าน Self-hosted กันบ้างดีกว่า ว่ามันต่างกันอย่างไร
Self-hosted
บริการนี้จะเป็นการที่เรา ติดตั้ง n8n เองตั้งแต่ ตั้งค่า Virtual Machine หรือ VM ติดตั้ง Tools ต่างๆ จนไปถึงลง ซอฟแวร์ n8n เองทั้งหมด
แม้ฟังดูเหมือนว่าจะฟรี แต่มันก็ไม่ได้ฟรีแบบจริงๆร้อยเปอร์เซ็นต์หรอกครับ ที่บอกว่าเหมือนจะฟรี ก็เพราะ n8n เขาจดสิทธิบัตร software ของเขา โดย based on fair-code model. นั้นเอง
Fair Code Model คือการจด license แบบที่เราสามารถเอา sourcecode ของเขาไปใช้ได้ แก้ไขปรับปรุงได้ แต่ก็อาจจะมีเงื่อนไขบางอย่างที่ไม่ได้รับการรับรองจากทาง OSI Approved Licenses เช่นการเก็บข้อมูลเป็นต้น
อย่างไรก็ตาม การเลือกใช้ Cloud Subscription หรือ Self-hosted นั้น ก็ขึ้นอยู่กับหลายปัจจัย อาทิ เช่น ความปลอดภัย การธรรมาภิบาลข้อมูล (Data Governance) และระดับความลับของข้อมูลเป็นต้น
เพราะฉะนั้นแล้ว เรามาดูกันดีกว่าว่า n8n แต่ละแบบมีการเก็บข้อมูลอย่างไรกันบ้าง เพื่อใช้ประกอบการตัดสินใจในการเลือกวิธีการใช้งาน
4. ข้อควรระวังในการใช้งานข้อมูล
สำหรับ n8n แบบ Self-hosted
- รหัสข้อผิดพลาดและข้อความ (Error codes & Messages): สำหรับการรันเวิร์กโฟลว์ที่ล้มเหลว ( Failed Executions ) โดยจะไม่เก็บข้อมูล Payload และข้อมูลจาก Custom Nodes (เช่น หากคุณมี Web Server Node ที่เรียกใช้บน n8n)
- รายงานข้อผิดพลาด (Error Reports): สำหรับกรณีที่ แอพ n8n เกิดข้อผิดพลาดร้ายแรง หรือปัญหาเชิงเทคนิคของ API
- โครงสร้างของเวิร์กโฟลว์ (Workflow Structure): เช่น สำหรับ Workflow นี้ใช้ Node อะไรบ้างเป็นต้น เช่น Gmail, Azure เป็นต้น
- พารามิเตอร์ของ Node (Node Parameters): จะเก็บ Operation กับ Resource เท่านั้น (ถ้ามี) และ สำหรับ HTTP Request Node ก็จะเก็บ Domain, Path และ Method โดยข้อมูลส่วนบุคคลจะทำให้เป็นแบบปกปิดข้อมูลแทน
- สถานะการทำงานของเวิร์กโฟลว์ (Workflow Execution Data):
- สถานะผลลัพธ์การทำงาน (เช่น 200 OK, 404 Not Found, 500 Internal Server Error)
- รหัสผู้ใช้งานที่เรียกใช้ Workflow นั้นบน n8n
- การโหลดข้อมูลครั้งแรกของเวิร์กโฟลว์จากแหล่งข้อมูลภายนอก
- การรันเวิร์กโฟลว์ที่ประสบความสำเร็จครั้งแรกในโหมด Production (ไม่ใช่การรันด้วยตนเอง)
- Domain ของ Webhook Calls (หากมีการระบุ): โดยไม่รวม Subdomain
- รายละเอียดการใช้งานหน้าจอผู้ใช้ (UI Usage): เช่น การนำทาง (Navigation) หรือการค้นหาใน Nodes Panel
- ข้อมูลการวินิจฉัย (Diagnostic Information): เช่น n8n version, การตั้งค่าที่เลือก (Selected Settings) อย่าง DB_TYPE, N8N_VERSION_NOTIFICATIONS_ENABLED, N8N_DISABLE_PRODUCTION_MAIN_PROCESS, ตัวแปรการรัน (Execution Variables), ระบบปฏิบัติการ (OS), RAM, และ CPU, Anonymous Instance ID, และ IP Address
- IP Address
จะเห็นได้ว่าถึงแม้ n8n จะพยายามหลีกเลี่ยงการเก็บข้อมูลส่วนบุคคลที่อาจขัดต่อ พ.ร.บ. คุ้มครองข้อมูลส่วนบุคคล (PDPA) หรือ GDPR แต่ก็ยังมีการเก็บข้อมูลทางเทคนิคและการใช้งานอยู่พอสมควร ซึ่งคุณควรพิจารณาในบริบทขององค์กรของคุณ
สำหรับ n8n แบบ Cloud Subscription
ในส่วนของ Cloud Subscription นั้น n8n จะมีการเก็บข้อมูลพื้นฐานเช่นเดียวกับ Self-hosted ทุกประการ และจะ เพิ่มเติม การเก็บข้อมูลบางส่วนเพื่อวัตถุประสงค์ในการปรับปรุงบริการและประสิทธิภาพของ AI ดังนี้:
- การจับการใช้งานหน้าจอ (Screen Recording Capture) เพื่อดูว่าผู้ใช้งานมีการเรียกใช้ node หรือการแสดงค่าอย่างไรบ้าง โดยปราศจากการเก็บข้อมูลส่วนบุคคล (ลบภายใน 21 วัน)
- การให้ AI chat เรียนรู้ ข้อมูล ณ ปัจจุบัน อย่าง workflow, context data I/O และ โค้ด ที่เขียนลงไปใน n8n เพื่อเพิ่มประสิทธิภาพในด้านประสบการณ์ผู้ใช้งาน (ลบภายใน 30 วัน)
5. มาลองติดตั้ง n8n กันเถ๊อะ
ก่อนอื่นเลยเราต้องมาอธิบายกันก่อนว่าอะไรคือ Docker และ อะไรคือ Docker Compose เพื่อที่เราจะได้เข้าใจเครื่องมือพื้นฐานสำคัญก่อนดำดิ่งสู่ของจริง
Docker คืออะไร ?
- Docker เป็น Open-Platform รูปแบบหนึ่งที่ให้นักพัฒนาสามารถที่จะ พัฒนา ใช้คำสั่ง และ ย้าย Application ของพวกเขาได้อย่างรวดเร็ว
- Docker ช่วยให้เราสามารถรัน Applications ของเราแยกกันบนโครงสร้างพื้นฐาน (Infrastructure)เดียวกันได้ ช่วยห้เราสามารถ deliver งานได้ไวขึ้นและสามารถทำให้เราใช้สิ่งที่คนอื่นสร้างไว้แล้ว อย่าง Image เพื่อทำให้ขึ้นงานได้ไวอีกด้วย
Docker Compose
- เป็นเครื่องมือที่ใช้ในการกำหนดและรัน container หลายๆอันพร้อมๆกันได้
- โดยปกติ เราจะต้องมานั่งรัน
docker buildและdocker runทีละ Dockerfile ใช่ไหมครับ มันช้า เขาก็เลยสร้างเครื่องมือตัวนี้ให้เราสามารถเขียน docker-compose.yml ไฟล์เดียวแล้วรัน containers ขึ้นมาพร้อมกันๆหลายๆอันได้เลย
สำหรับบทความนี้เราจะไม่ได้อธิบายวิธีการติดตั้ง Docker และ Docker Compose นะครับ แต่ทุกท่านสามารถดูวิธีการติดตั้งได้โดยคลิกที่นี้
DigitalOcean Droplet
ใน Tutorial นี้เพื่อให้เหมือนกับของจริงเวลาคุณได้เครื่อง VM จาก Cloud ภาครัฐ GDCC หรือ Cloud จากทีม Network ของคุณสร้างให้ เราจะใช้ VM จากทาง DigitalOcean Droplets นะครับ
DigitalOcean Droplets
- Virtual Machine ที่เป็น linux-based ออนไลน์อยู่บน hardware เสมือนจริงที่ทาง DigitalOcean เป็นคนสร้างให้
สำหรับบทความนี้เพื่อนๆสามารถดูวิธีการติดตั้ง Droplet โดยคลิกลิ้งค์นีได้เลยนะครับ หากไม่สะดวกภาษาอังกฤษ ผมแนะนำว่าให้ Copy เนื้อหาแล้วเอาไปแปะให้ AI แปลให้จะสะดวกมากๆเลยครับ
สมมติว่าคุณได้ Droplet มาเรียบร้อยแล้ว ขั้นตอนแรกคือการเชื่อมต่อไปยังเซิร์ฟเวอร์ของคุณผ่าน Terminal
ssh -i ~/.ssh/<public_ssh_key> <username>@<droplet_ip>
ถ้าคุณเลือกว่าจะใส่ passphrase ระบบก็จะถามเราก็ใส่ passphrase ให้ถูกตามที่เรากรอก หรือถ้าเราเป็นคนขี้เกียจก็ ssh-add <ssh_private_key> ไปก็จะไม่ต้องใส่ passphrase ทุกรอบ
เมื่อ log in เข้ามาแล้ว ผมแนะนำว่าให้สร้าง user ใหม่แทนนะครับเพื่อความปลอดภัย และหลีกเลี่ยงการใช้ Root user
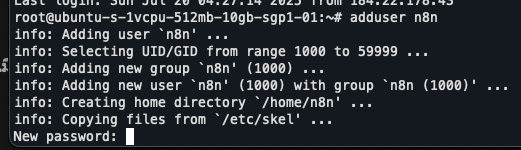
สมมติว่าคุณได้ Droplet มาเรียบร้อยแล้ว ขั้นตอนแรกคือการเชื่อมต่อไปยังเซิร์ฟเวอร์ของคุณผ่าน Terminal:
adduser <username>
ระบบก็จะให้เรากรอกข้อมูลต่างๆ เราก็ค่อยๆกรอกไป ก็จะมีทั้ง รหัสผ่าน, ชื่อ, ที่ทำงาน, เบอร์โทรศัพท์ เป็นต้น
จากนั้นเราก็ให้สิทธิ์ admin กับ user ของเรา
usermod -aG sudo <username>
ทีนี้เราก็สามารถเรียกใช้คำสั่งที่ต้องอาศัยสิทธิ์ super user ได้แล้ว โดยสามารถใส่ sudo ด้านหน้าเพื่อใช้ง
จากนั้นเราก็ทำการสร้าง ssh key อันใหม่สำหรับ user นี้เพื่อที่เราจะได้ ssh จากเครื่องเราได้และไม่ต้องผ่าน root อีกต่อไป Add Public Key Authentication.
เมื่อทำเสร็จแล้วก็ exit ออกจากเครื่อง Vm และทำการ ssh เข้าไปใหม่ด้วย user ที่เราสร้างนั้นเอง
ssh -i ~/.ssh/id_n8n_admin <username>@<droplet_ip>
Clone Project และเตรียม Docker Volumes
เอาหละเมื่อได้ user ใหม่แล้วเราก็ต้องทำการ clone project ลงมา
git clone https://github.com/n8n-io/n8n-docker-caddy.git
เมื่อ clone เสร็จแล้ว เราก็จะทำการเปลี่ยน directory ก่อน
cd n8n-docker-caddy
ls

สำหรับตรงจุดเดี๋ยวเราจะวนกับมาอธิบายเพิ่มเติมหลังจากที่เราได้เปิดดู docker-compose.yml
เพื่อให้เวลาเรา build docker container เป็นไปอย่างรวดเร็วและข้อมูลคงอยู่ถาวร เราควรสร้าง Docker Volume เก็บไว้ โดยในที่นี้เราจะสร้าง 2 ตัว นั้นคือสำหรับ caddy เพื่อเก็บ cache และ n8n_data นั้นเอง
sudo docker volume create caddy_data
sudo docker volume create n8n_data
จากนั้นเพื่อให้ n8n ของเรารันในฐานะ Web Application ได้ เราก็จะต้องเปิด port 80 สำหรับ non-secure traffic และ 443 สำหรับ secure traffic ด้วยการเรียกใช้คำสั่งด้านล่างจะเป็นการเปิด port ใน Firewallครับ
sudo ufw allow 80
sudo ufw allow 443
ละก็มาถึงส่วนที่สำคัญที่สุดนั้นคือไฟล์ docker-compose.yml
version: "3.7"
services:
caddy:
image: caddy:latest
restart: unless-stopped
ports:
- "80:80"
- "443:443"
volumes:
- caddy_data:/data
- ${DATA_FOLDER}/caddy_config:/config
- ${DATA_FOLDER}/caddy_config/Caddyfile:/etc/caddy/Caddyfile
n8n:
image: docker.n8n.io/n8nio/n8n
restart: always
ports:
- 5678:5678
environment:
- N8N_HOST=${SUBDOMAIN}.${DOMAIN_NAME}
- N8N_PORT=5678
- N8N_PROTOCOL=https
- NODE_ENV=production
- WEBHOOK_URL=https://${SUBDOMAIN}.${DOMAIN_NAME}/
- GENERIC_TIMEZONE=${GENERIC_TIMEZONE}
volumes:
- n8n_data:/home/node/.n8n
- ${DATA_FOLDER}/local_files:/files
volumes:
caddy_data:
external: true
n8n_data:
external: true
services: ส่วนนี้ใช้กำหนดบริการ (Services) ต่างๆ ที่จะถูกสร้างเป็น Container โดยในที่นี้คือ Caddy (Web Server/Reverse Proxy) และ n8n
volumes: กำหนด External Volumes ที่เราสร้างไว้ก่อนหน้านี้ (caddy_data และ n8n_data) เพื่อใช้เป็น Persistent Storage ให้กับ Container
image: ระบุ Docker Image ที่จะใช้สำหรับสร้าง Container ซึ่งจะดึงมาจาก Docker Hub
restart: เป็น Tag ที่กำหนดพฤติกรรมการ Restart ของ Container หากหยุดทำงาน
unless-stopped(สำหรับ Caddy): Container จะ Restart อัตโนมัติ ยกเว้นคุณเป็นคนสั่งหยุดเองalways(สำหรับ n8n): Container จะ Restart อัตโนมัติเสมอ ไม่ว่าจะหยุดทำงานด้วยสาเหตุใดก็ตาม- ข้อแตกต่างคือ หากคุณใช้คำสั่ง
docker compose stopแบบalwaysจะรีสตาร์ทเองทันที แต่unless-stoppedคุณต้องสั่งdocker compose upใหม่
ports: ใช้กำหนดการเชื่อมโยง Port ระหว่าง Container ภายใน กับ Port ของเครื่อง VM ภายนอก (เช่น - 80:80 คือ Port 80 ภายนอกเชื่อมไป Port 80 ภายใน Container)
environment: ใช้กำหนดตัวแปรสภาพแวดล้อม (Environment Variables) ภายใน Container ซึ่งจำเป็นสำหรับการตั้งค่าการทำงานของ n8n (เช่น Host, Port, Protocol, Timezone และ Webhook URL)
เรามาดูกำหนดค่าใน .env แต่ละอันกันดีกว่าครับ
# Replace <directory-path> with the path where you created folders earlier
DATA_FOLDER=/<directory-path>/n8n-docker-caddy
# The top level domain to serve from, this should be the same as the subdomain you created above
DOMAIN_NAME=example.com
# The subdomain to serve from
SUBDOMAIN=n8n
# DOMAIN_NAME and SUBDOMAIN combined decide where n8n will be reachable from
# above example would result in: https://n8n.example.com
# Optional timezone to set which gets used by Cron-Node by default
# If not set New York time will be used
GENERIC_TIMEZONE=Europe/Berlin
# The email address to use for the SSL certificate creation
SSL_EMAIL=example@example.com
ถ้าเป็นของผม ผมก็จะกรอกแบบนี้ ข้อควรระวัง ตอนติดตั้งจริงๆ เนี้ยควรใช้ เป็น /etc เพื่อความปลอดภัยนะครับ
# Replace <directory-path> with the path where you created folders earlier
DATA_FOLDER=/demo/n8n-docker-caddy # ผมแนะนำว่าให้สร้างที่อื่นนะครับของจริง ผมสร้างใน /etc
# The top level domain to serve from, this should be the same as the subdomain you created above
DOMAIN_NAME=patrawi.com
# The subdomain to serve from
SUBDOMAIN=n8n
# DOMAIN_NAME and SUBDOMAIN combined decide where n8n will be reachable from
# above example would result in: https://n8n.example.com
# Optional timezone to set which gets used by Cron-Node by default
# If not set New York time will be used
GENERIC_TIMEZONE=Asia/Bangkok
# The email address to use for the SSL certificate creation
# SSL_EMAIL=example@example.com
เมื่อกำหนดเสร็จแล้วเราก็ต้องเข้าไปแก้ใน Caddy ต่อ เพื่อที่ Caddy จะได้ Reverse Proxy ทุก Ports ไปยัง Port 5678
n8n.<domain>.<suffix> {
reverse_proxy n8n:5678 {
flush_interval -1
}
}
สำหรับตรงนี้ผมก็จะแก้เป็น n8n.patrawi.com ที่เป็น domain ที่ผมซื้อไว้นั้นเอง อย่างไรก็ตาม หากเป็นการใช้งานในหน่วยงานของท่าน คุณจะต้องแจ้งทีม Network ให้เขากำหนด subdomain และ DNS recordให้เราอีกทีนะครับ เพื่อที่ DNS มองเห็น IP Address ของ VM ของคุณครับ
เริ่มต้นและตั้งค่า DNS
เมื่อแก้ Config ทั้งหมดเสร็จแล้ว ได้เวลา Spin up Container ของเราแล้วเย้
sudo docker compose up -d
แต่ว่าพอคุณ เปิดไปที่ dns ที่คุณกำหนดแล้ว คุณก็จะพบว่าข้อความ Can’t Reach This Server สาเหตุก็เป็นเพราะว่า DNS ของเรานั้นยังไม่ได้นำไปผูกกับ IP Address ที่ DigitalOcean นั้นเองเราก็จะต้องไปทำตรงนั้นกันก่อน
*หมายเหตุ ถ้าเราให้ทีม network ของหน่วยงานเราเป็นคนสร้าง vm ขึ้นมาให้ตรงจุดนี้จะไม่มีปัญหานะครับ แต่จะไปมีปัญหาเรื่อง SSL/TLS แทนเดี๋ยวผมจะวนมาอธิบายให้ฟังอีกทีครับ
ขั้นตอนการตั้งค่า DNS บน DigitalOcean (หรือผู้ให้บริการ DNS ของคุณ):
- เข้าไปที่ Dashboard ของ Droplet และเลือก Networking
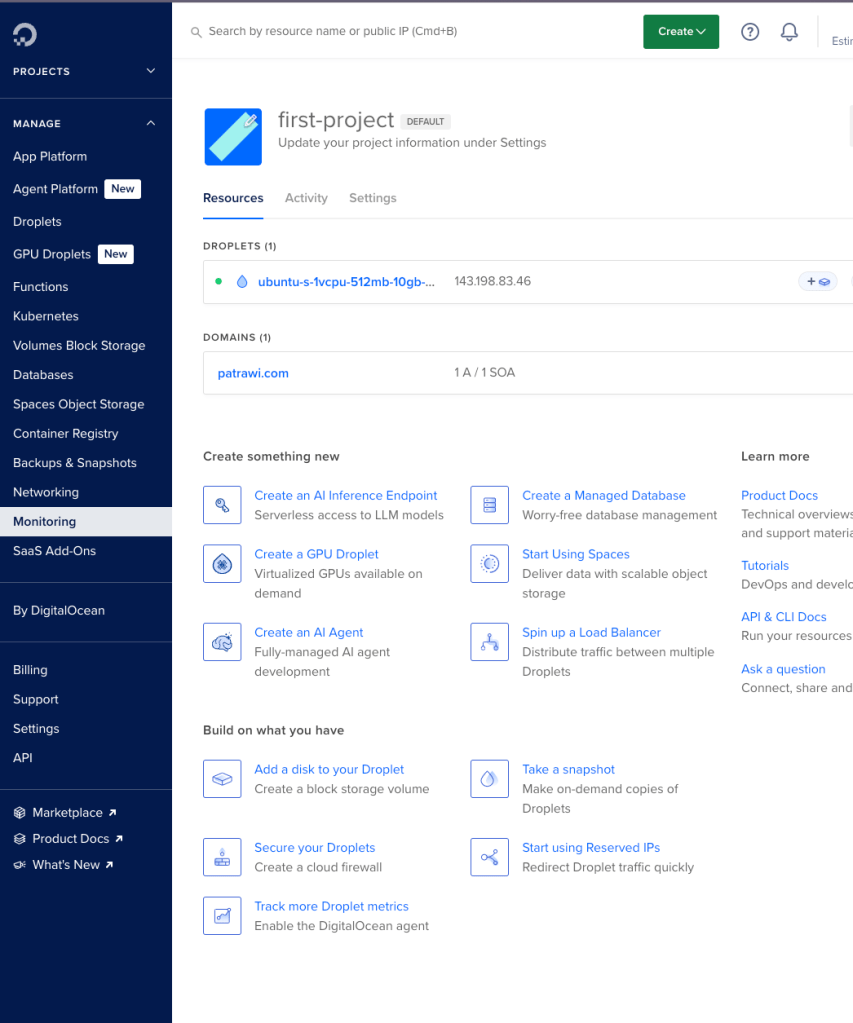
2. เลือก Tab Domains และใส่ Domain ที่ซื้อมา

3. กรอก Domain ที่คุณซื้อมาลงในช่องว่าง
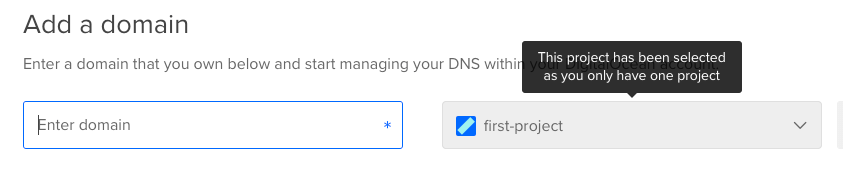
4. สร้าง A Record แล้วเขียน Hostname เป็น n8n.patrawi.com (หรือ Subdomain ที่คุณต้องการ) และ Value ก็เลือกเป็น IP Address ของ VM ที่เราสร้าง
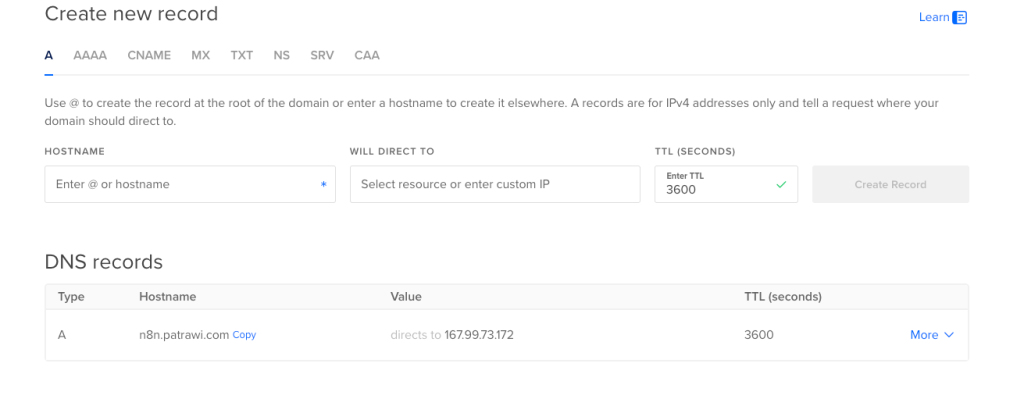
เนื่องจากว่าปัจจุบัน blog นี้เป็น blog ที่บริหารและดูโดย WordPress รวมไปถึง Domainname ด้วย เพราะฉะนั้นผมจึงเลือกให้ WordPress เป็นคนบริหาร Domainname ด้วยเหตุนี้ผมจึงไม่มี NS Record ที่ชี้ไปที่ DigitalOcean
ถ้าเป็นของทุกคนที่มาทำครั้งแรก จะมี NS ที่ชี้ไปที่ digitalocean อยู่ 3 อันให้ทำการลบออกด้วยนะครับ ถ้ากรณีจะให้ผู้ให้บริการเจ้าอื่น บริหารตรงจุดนี้
หลังจากที่คุณตั้งค่า DNS ที่ผู้ให้บริการ Domain ของคุณเรียบร้อยแล้ว (เช่นในกรณีของผมที่ซื้อ Domain ผ่าน WordPress) คุณจะต้องแจ้งผู้ให้บริการ DNS ทราบว่า การเรียก Subdomain n8n นี้ ให้ Redirect ไปยัง IP Address ของ Droplet ของคุณ

เมื่อดำเนินการเสร็จสิ้น คุณจะต้องรอสักระยะเพื่อให้ DNS Server ต่าง ๆ ทั่วโลกอัปเดตข้อมูล (Propagation) คุณสามารถตรวจสอบสถานะได้โดยใช้คำสั่ง
dig <dns_name>
หากขึ้นว่า NXDOMAIN หมายความว่า DNS Server นั้นยังไม่รู้จัก Domain ของคุณ ต้องรอต่อไปจนกว่าจะขึ้นว่า NOERROR นั่นแปลว่าคุณพร้อมใช้งานแล้วครับ!
ทดสอบการติดตั้งและข้อสังเกตเกี่ยวกับ SSL/TLS
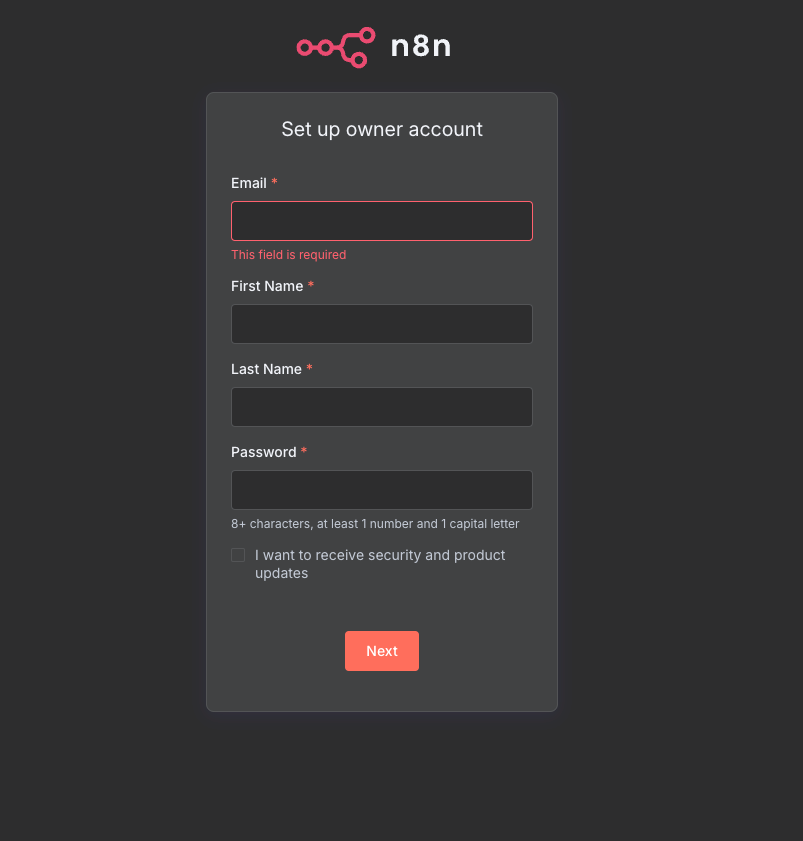
เมื่อคุณลองเข้าถึง DNS Server ดังกล่าว และเห็นหน้าตาดังกล่าว:
ยินดีด้วย! คุณติดตั้ง n8n server สำเร็จแล้ว!
แต่เดี๋ยวก่อน! ก่อนที่เราจะจบบทความส่วนนี้ จำเรื่อง SSL/TLS ที่ผมทักไว้ได้ไหมครับ? ปัญหาคือ ปกติเมื่อเราใช้บริการผู้ให้บริการ DNS และ Server อย่าง DigitalOcean หรือ WordPress (ในกรณีของผม) พวกเขาจะดูแลจัดการเรื่อง SSL/TLS (ใบรับรองความปลอดภัย) ให้เรียบร้อย ทำให้ไม่มีปัญหาอะไร
แต่ถ้าในกรณีที่คุณติดตั้ง n8n บนเครื่อง VM ที่คุณ Hypervise บน Hardware ของคุณเองล่ะ?
ใช่ครับ! คุณจะต้องเป็นคนจัดการส่วนนี้เองทั้งหมด (เช่น การขอใบรับรอง SSL/TLS และการตั้งค่าให้ Web Server ใช้งาน) แต่ส่วนตัวผมคิดว่าหากลงรายละเอียดส่วนนี้ไปในตอนนี้ บทความจะยาวเกินไป และอาจทำให้เนื้อหาหลักเรื่องการติดตั้ง n8n เสียโฟกัสครับ
สำหรับโพสต์นี้ การติดตั้ง n8n บน VM ถือว่าเสร็จสมบูรณ์แล้วครับ! และในส่วนสุดท้ายของบทความนี้ เมื่อเราติดตั้งสำเร็จแล้ว ก็ถึงเวลาที่จะมาลองสร้าง Workflow ง่ายๆ กันบ้าง เพื่อให้คุณเห็นภาพการทำงานจริงครับ
6. ทดลองทำ Workflow ง่ายๆ 1 อัน
ในส่วนนี้ ผมจะพาทำ Workflow ง่ายๆอย่างการดึงฟีดข่าวจาก Blognone แล้วนำไปโพสต์ใน Discord เพื่อที่เราจะได้ติดตามข่าวสารได้อย่างตลอดเวลาและตามทันโลกที่หมุนเร็วเสียยิ่งกว่าอะไร
หลังจากที่เรากรอก Username, Password, Email ของ Admin เราก็จะเข้ามาที่หน้า Dashboard ที่หน้าตาอาจจะไม่เหมือนกับของผมหรอก แต่องค์ประกอบโดยรวมน่าจะคล้ายๆกัน
1. สร้าง Workflow ใหม่
จากนั้นให้เพื่อนๆคลิกไปที่ปุ่ม Create Workflow เพื่อสร้างหน้า Workflow อันใหม่ครับ

ทุกคนจะได้หน้า freeform แบบนี้ครับผม โดยมี สี่เหลี่ยมบวกอยู่ตรงกลาง
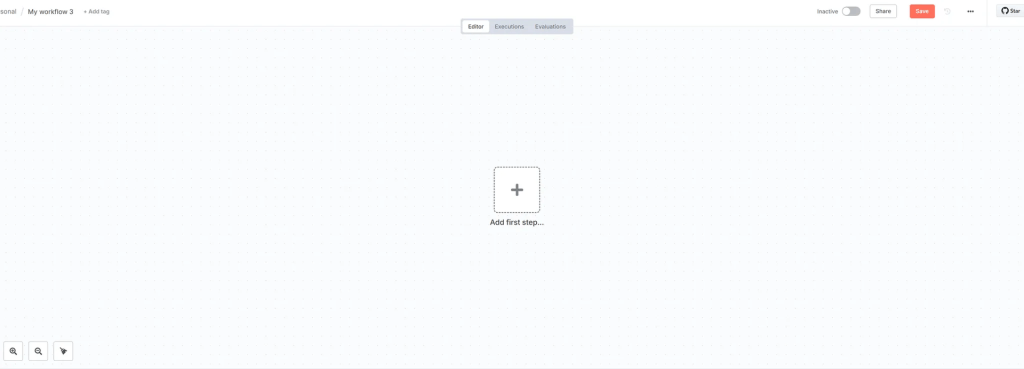
2. ตั้งชื่อ Workflow
คลิกตรง My workflow เพื่อทำการเปลี่ยนชื่อให้สื่อความหมาย เพราะเวลาเรากลับมาแก้เราจได้รู้ว่าอันไหนเป็นอันไหนนะครับ
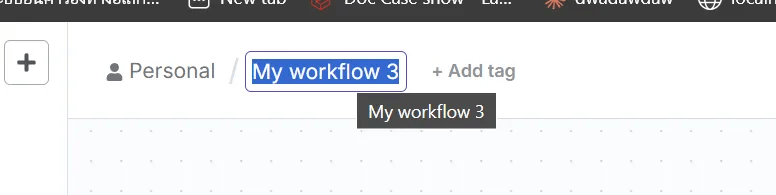
แก้เสร็จแล้วก็ กดปุ่มตรงกลางได้เลยยย

3. ตั้งค่า Trigger (RSS Feed)
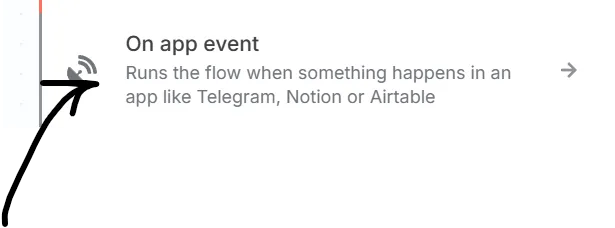
เมื่อกดแล้วจะมี แทบขึ้นมาด้านขวาใช่ไหมครับ ตรงส่วนนี้เราเรียกว่า Trigger อธิบายแบบง่ายก็คือเราจะให้ Workflow นี้เริ่มทำงานอย่างไร เดี๋ยวผมจะมีอีก โพสที่มาขยายความตรงนี้นะคับ แต่เบื้องต้นให้ทุกคนเลือก On App Event
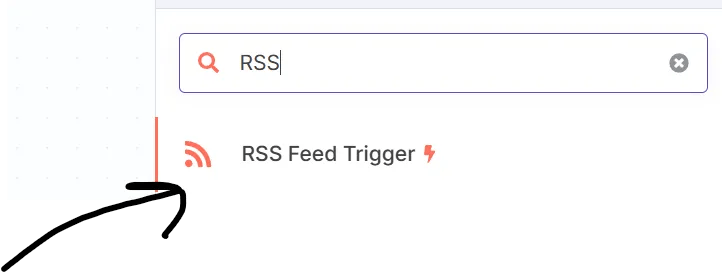
เมื่อคลิกไปแล้วก็จะได้ ช่อง Search มาพร้อมกับหลายชื่อ Node ต่างๆ สำหรับการ Integration นะครับ สำหรับเนื้อหาวันนี้ขอให้พิมพ์ RSS ในช่องค้นหาครับผม และเลือก RSS Feed Trigger
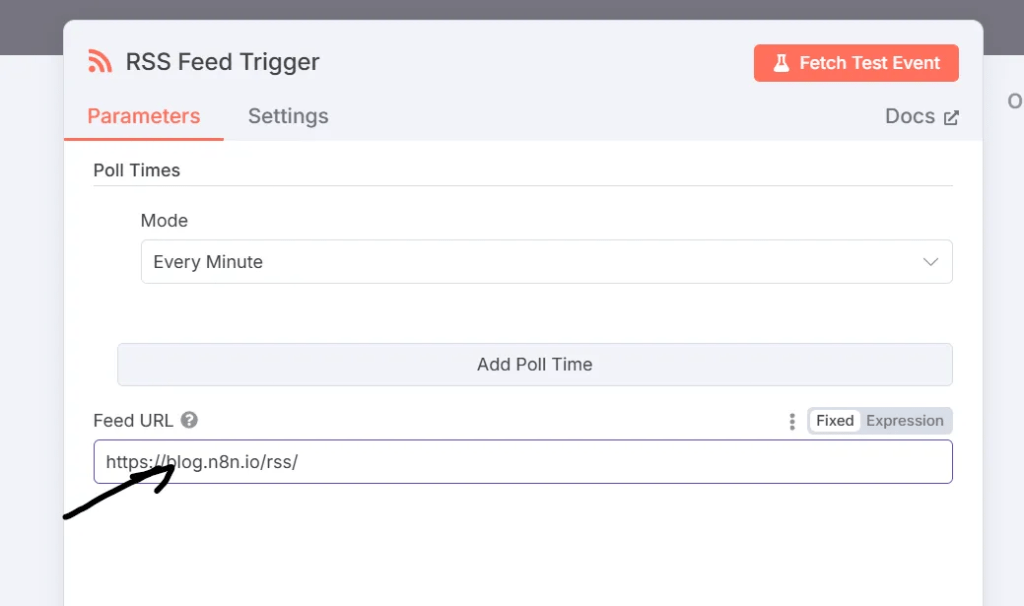
จากในรูปนี้ให้เราอย่าพึ่งไปสนใจตัว Poll Times โฟกัสไปที่ Feed URL ก่อน สำหรับในช่องนี้ ผมเลือกใช้ RSS Feed ของทาง blognone
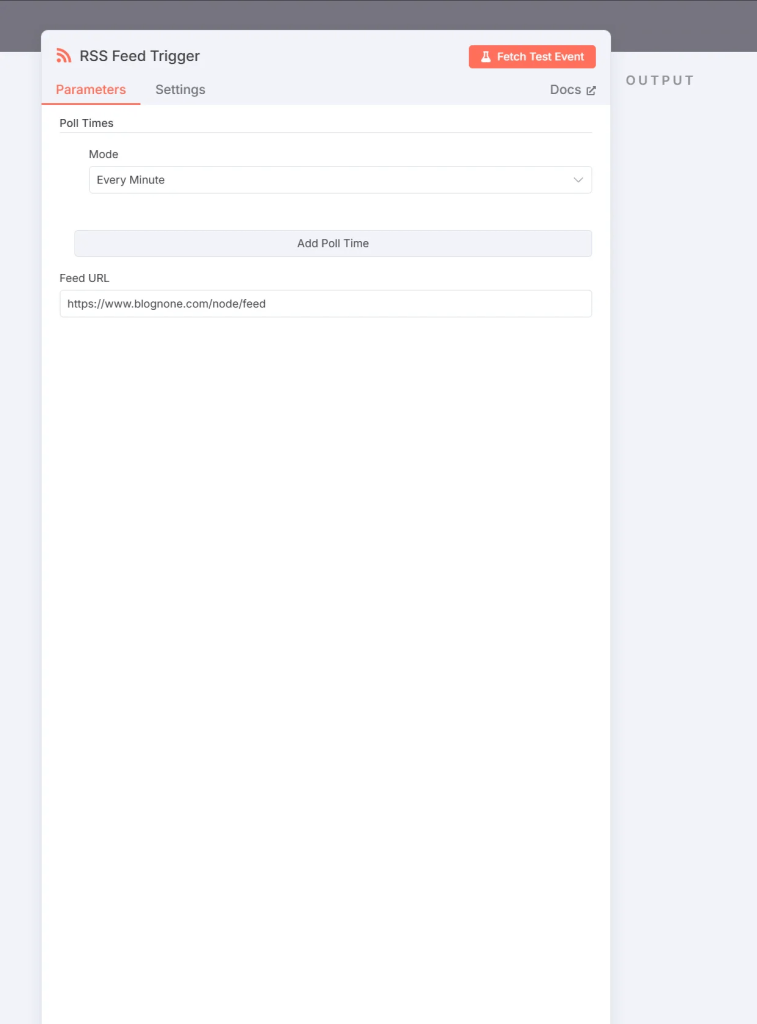
จากนั้นก็ลองกด Fetch Test Event เพื่อทดสอบผลลัพธ์
เมื่อกดแล้วด้านขวาก็จะเป็น json ที่เราเรียกออกมานั้นเอง

แต่อย่างที่ทุกคนเห็นเรายังไม่สามารถเอาลักษณะนี้ไปใช้ได้ เราต้องมีการจัดรูปแบบ JSON ก่อน ให้เพื่อนๆปิด ฟอร์มนี้ไปก่อนนะครับแล้วกด + เพื่อเพิ่มเมนู Data Transformation ต่อไป
4. จัดรูปแบบข้อมูลด้วย Data Transformation (Edit Fields)
การทำ Data Transformation คือการที่เราแก้ไข กรอง และแปรงข้อมูลให้อยู่ในรุปแบบต่างๆแทนนะครับ
ในหน้า Data Transformation ให้เลือก “Edit Field”
ในฟอร์มนี้ คุณสามารถ Drag & Drop Field ที่คุณต้องการใช้จากข้อมูล JSON ทางด้านซ้าย มาวางในช่องว่างตรงกลางได้เลยครับ
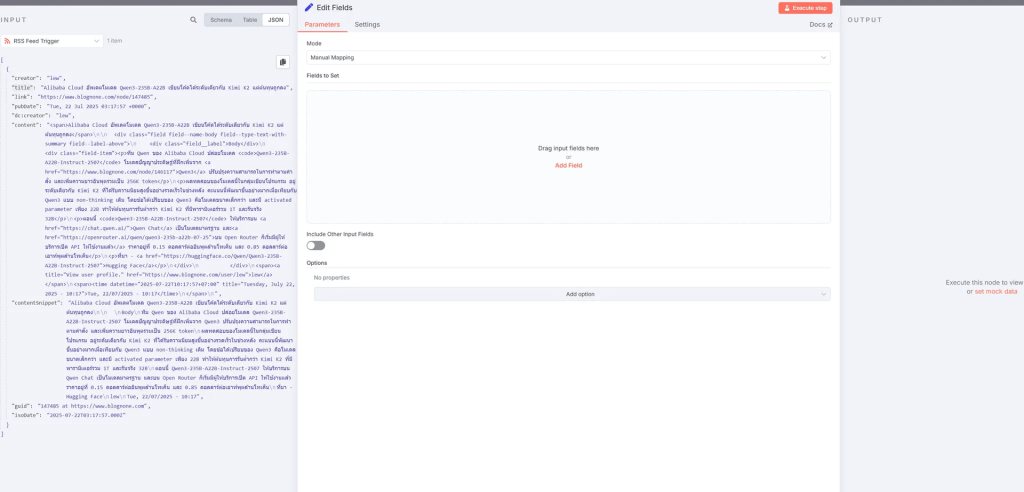
ว่าแต่ แล้ว JSON คืออะไร ผมขอแวะอธิบายตรงนี้นิสสนึงนะครับ เพื่อไม่ให้เพื่อนๆสงสัย
JSON คืออะไร
JSON ย่อมาจาก JavaScript Object Notation เป็นรูปแบบข้อมูลประเภทหนึ่งที่นิยมใช้ในการส่งผ่านข้อมูลบน Protocol HTTP นั้นเอง โดยจะมีลักษณะการเก็บข้อมูลเป็น Key (ชื่อข้อมูล) และ Value (ค่าของข้อมูล)
ตัวอย่างเช่น: หากมี Key คือ “Title” และ Value เป็น “Alibaba Cloud อัปเดตโมเดล Qwen3-235B-A22B เขียนโค้ดได้ระดับเดียวกับ Kimi K2 แต่ต้นทุนถูกลง” นั่นหมายความว่าหัวข้อข่าวคือข้อความนั้นนั่นเอง
5. เชื่อมต่อและส่งข้อมูลไปยัง Discord
โอเคเรากลับมาต่อที่เนื้อหากันดีกว่า หลังจากที่เราได้ มา 2 Node แล้วทีนี้ก็ถึงเวลาส่งข้อมูลกันแล้วครับ
ให้เพื่อนๆ กด + แล้วก็จะได้หน้าตาแบบด้านล่างมาใช่ไหมครับ
พิมพ์ลงไปว่า discord ดังรูป และเลือก เมนู Discord
จากนั้นให้ทำการมองหาคำว่า Send a Message แล้วคลิกไปได้เลยครับ
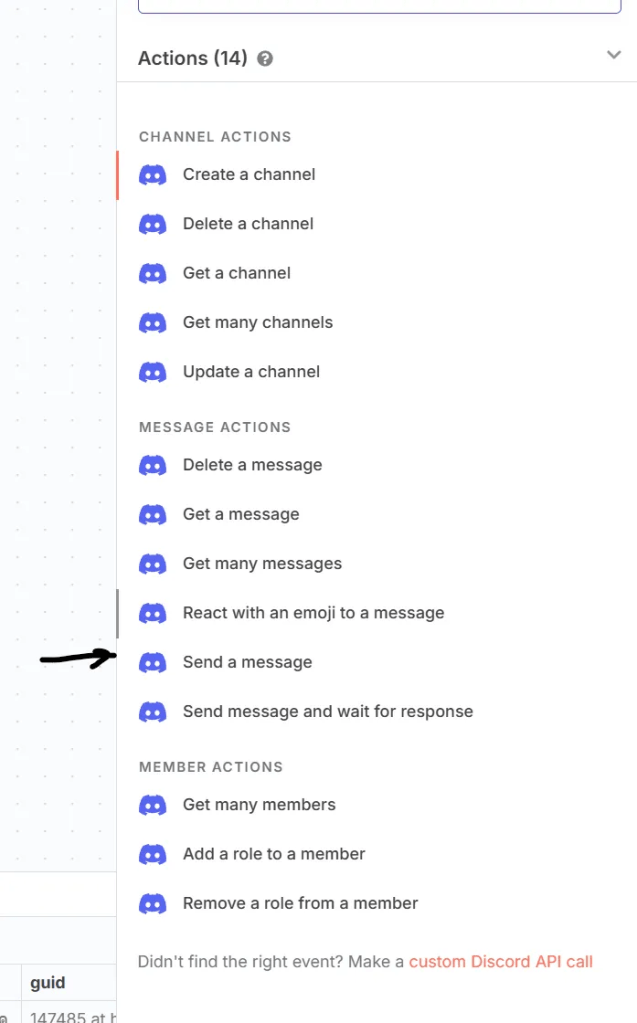
เพื่อนจะได้หน้าตา มาแบบนี้ใช่ไหมครับ ให้เพื่อนๆ เลือก ตรง Connection Type แล้วมองหาคำว่า Webhook

ถามว่าทไมต้องเป็ฯ Webhook นอกจากจะเป็นวิธีที่เร็วและสะดวกที่สุดในการทำ RSS Feed Message Channel แล้ว ยังเป็นวิธีที่ง่ายที่สุดเมื่อเทียบกับอีก 2 ข้อนั้นเองครับ

เมื่อเลือกมาแล้วให้เพื่อนๆ คลิก Create new Credential
6. สร้าง Webhook URL จาก Discord
ตอนนี้เราต้องสลับไปที่แอปพลิเคชัน Discord เพื่อไปคัดลอก Webhook URL มา

เข้าไปที่ Text Channel ที่เราสนใจ และคลิกตรงรูปฟันเฟือง
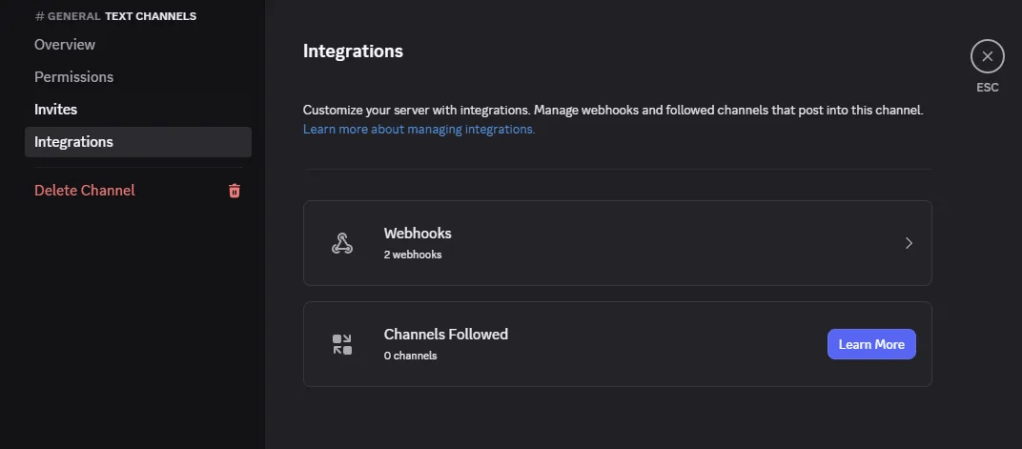
เลือก Tab Integration แล้ว กด Webhook

หลังจากนั้นให้กด New Webhook
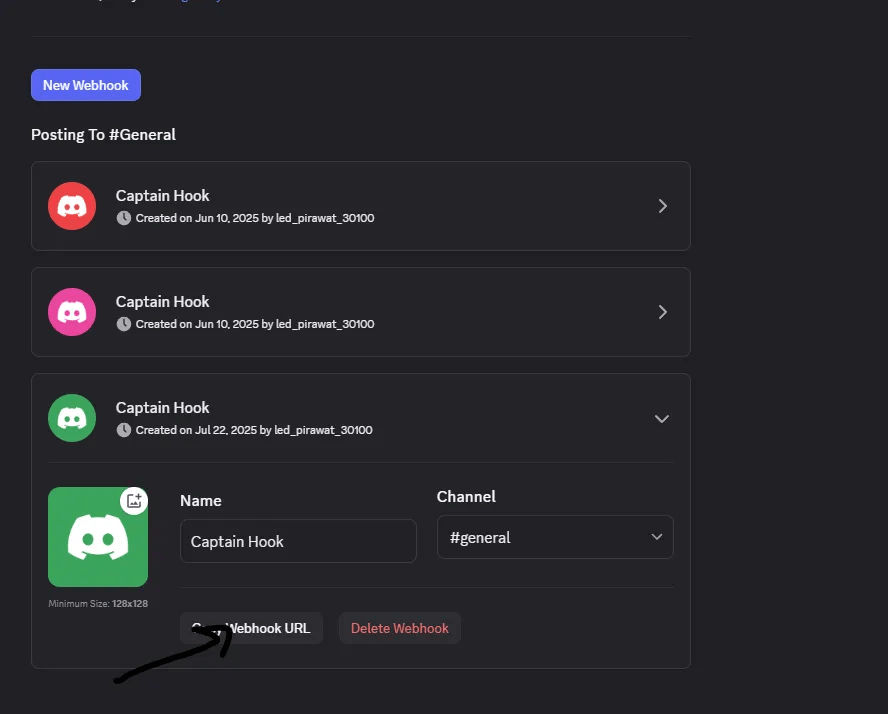
เปลี่ยนชื่อ และ กด Copy Webhook URL
7. วาง Webhook URL และจัดรูปแบบข้อความใน n8n

Paste Webhook URL ที่คัดลอกมาจาก Discord ลงในช่องว่าง
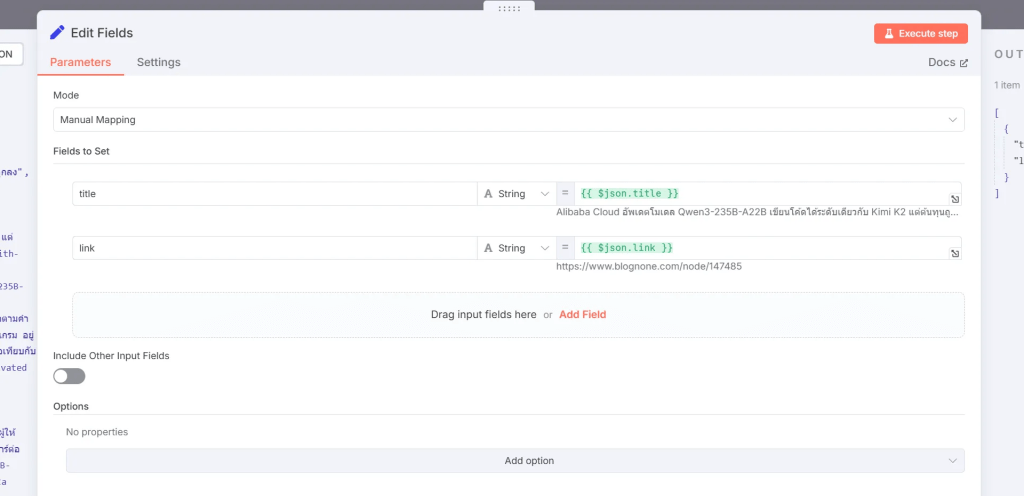
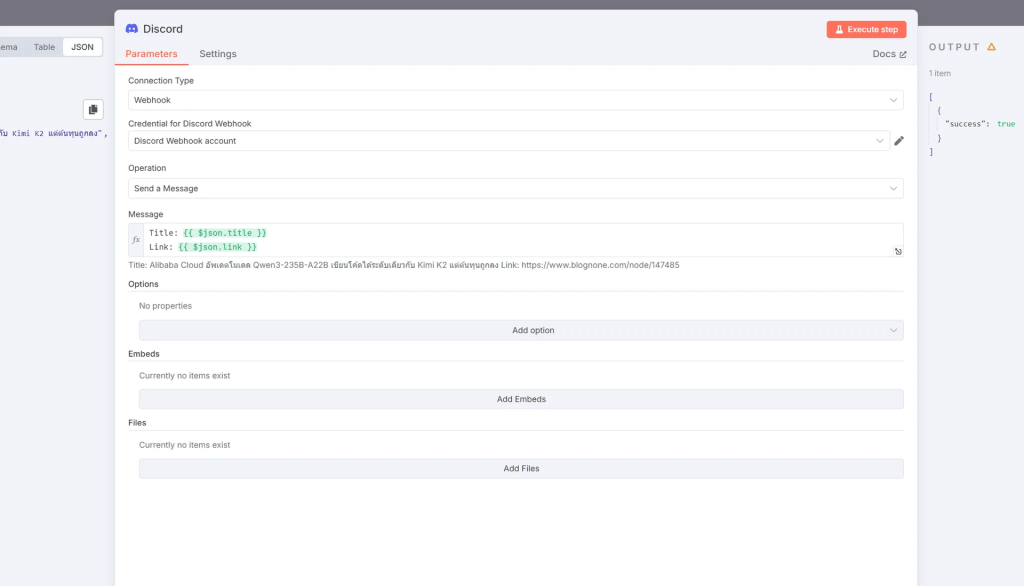
จัดรูปแบบข้อความที่จะโพสต์ใน Discord Node ของคุณ (เช่น การดึง Field Title หรือ Link จากขั้นตอน Data Transformation มาใช้ในข้อความ)

สิ้นสุด Workflow แรก!
และเราก็ทำ Workflow แรกเสร็จเรียบร้อยแล้ว หลังจากที่คุณตั้งค่าและจัดรูปแบบข้อความเสร็จ อย่างลืมกด Save และเปิดใช้งาน Workflow กันด้วยนะครับ

7. บทสรุป
เป็นอย่างไรกันบ้างครับ กับของเล่นใหม่ที่ผมอธิบายในวันนี้ ผมหวังว่าเพื่อนๆจะสามารถนำไปประยุกต์ใช้กันได้อย่างหลากหลาย และ สร้างสรรค์นะครับ
ถ้าเพื่อนๆสงสัยอะไร สามารถสอบถามได้ใน Comment ได้เลยครับ ยินดีตอบครับผม
แล้วในบทความถัดไป ผมจะมีเรื่องอะไรมาอธิบาย อย่าลืมติดตามกันนะครับ